

The Essence of Transformation from Data Lake to Data Mesh

Here to share my experience in the realm of expertise:
Cloud Adoption Applied AI, ML & MLOps Microservices 2.0 Digital Portfolio & Product P&L Federated Learning (Adv. AI) IaC, X-Ops, Containers, CaaS (Container-as-a-Service| Kubernetes), CaaS Governance (HELM) Digital Product UX/UI/LCNC (PWA/Micro frontend/ Low Code No Code canvass/ Self Service Interface) Distributed Computing Cybersecurity Industry 4.0 (IIoT, Intelligent Operation Platform, OT & IT) Blockchain in Data Trust Data & Digital Transformation
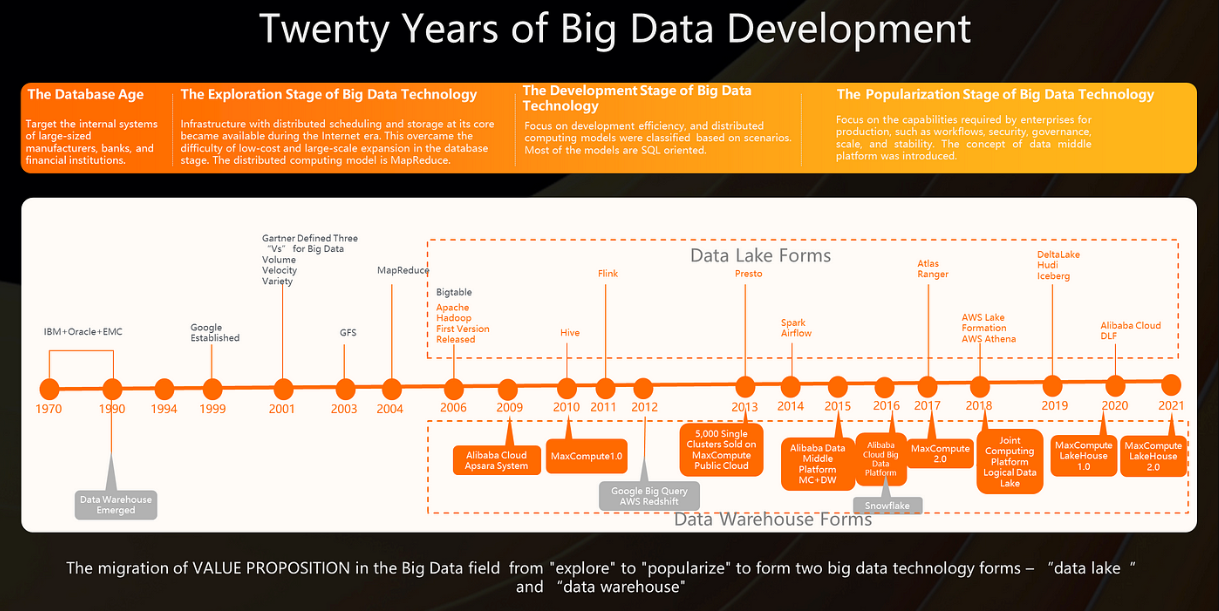
In recent years, major organizations worldwide have been experiencing significant transformations in their data management strategies. One of the most notable changes is the decentralization of data lakes into a concept known as data mesh. As an expert in the field, having worked in the analytics space for a leading Australian bank, I have witnessed firsthand the disruptive yet promising nature of this shift. In this article, we will explore the reasons behind the rise of data mesh, its potential benefits, and how organizations can implement a mesh infrastructure to unlock the full potential of their data.
A Brief History of Data Lakes:
Over the past decade, data lakes emerged as a popular solution for storing and analyzing large volumes of unstructured data. The rise of smartphones, IoT, digital media, and e-commerce created a pressing need for scalable data storage and analysis. Data lakes, powered by frameworks like Apache Hadoop, offered a flexible and cost-effective solution, enabling organizations to leverage big data for insights without predefined schemas.
The Data Lake Monster:
While data lakes initially promised flexibility and scalability, many organizations encountered challenges that transformed them into data swamps. Three main issues arose:
Problem 1: Centralized Conundrums - Central data teams were overwhelmed with the task of handling data from various domains, leading to scalability issues and becoming a bottleneck for organizational agility.
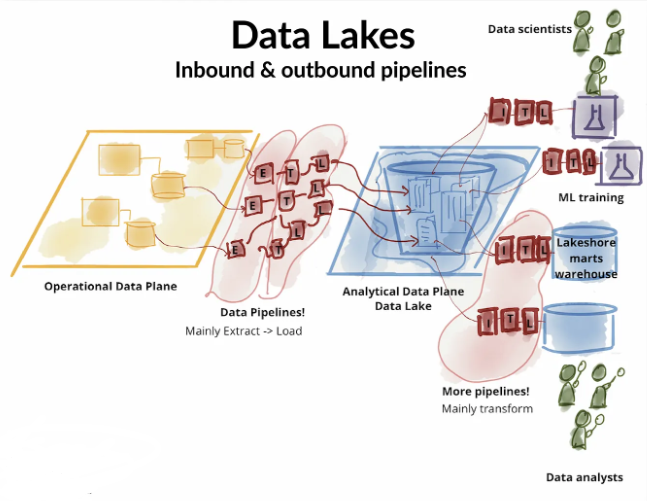
Problem 2: Lethargic Operating Model - Data lakes relied on a highly-coupled pipeline approach, making it difficult to adapt to changing data needs and slowing down the delivery of insights.
Problem 3: Fence-Throwing - Data engineers worked in isolation from data producers and consumers, resulting in disconnected teams, frustrated consumers, and overworked data platform teams.
Introducing Data Mesh:
Data mesh, proposed by Zhamek Dehghani, offers a decentralized approach to data management, addressing the limitations of data lakes. Its core principles aim to empower domain-specific teams and promote collaboration, ownership, and scalability.

Principle 1: Domain Ownership of Data - Data ownership is shifted to domain-specific teams, empowering them to take responsibility for data quality, reliability, and accessibility.
Principle 2: Federated Computational Governance - Domain teams manage their data processing pipelines, ensuring agility and faster decision-making while leveraging diverse tools and technologies.
Principle 3: Product Thinking Applied to Data - Treating data as a product encourages teams to focus on creating reusable, discoverable, and reliable data assets.
Principle 4: Self-serve Data Infrastructure as a Platform - Providing domain teams with self-serve infrastructure and tools fosters innovation, collaboration, and a sense of ownership.

Building a Data Mesh Infrastructure:
Implementing a data mesh infrastructure requires a careful approach and collaboration across the organization. Key steps include:
Step 1: Identify Domains and Data Products - Define the business domains and identify the data products that each domain team will be responsible for.
Step 2: Empower Domain Teams - Provide domain teams with the necessary resources, tools, and training to take ownership of their data.
Step 3: Establish Federated Governance - Define clear guidelines, standards, and collaboration mechanisms to ensure seamless data sharing and interoperability.
Step 4: Enable Self-serve Infrastructure - Invest in scalable data platforms, cloud-based solutions, and automation to empower domain teams and promote innovation.
Step 5: Foster a Data-driven Culture - Cultivate a culture that values data ownership, collaboration, and continuous improvement to maximize the potential of data mesh.
Conclusion:
Data mesh represents a paradigm shift in data management, addressing the limitations of centralized data lakes and promoting scalability, reliability, and collaboration. By empowering domain-specific teams and treating data as a product, organizations can unlock the full potential of their data assets.
Thank you for joining! Stay connected with the latest updates and insights by visiting my website www.DeepHiveMind.com. Don't forget to follow me on social media for more tech tips and discussions. Let's continue exploring the exciting world of technology together! #TechTalks #StayConnected




