

MLOps - A Brief Introduction

Here to share my experience in the realm of expertise:
Cloud Adoption Applied AI, ML & MLOps Microservices 2.0 Digital Portfolio & Product P&L Federated Learning (Adv. AI) IaC, X-Ops, Containers, CaaS (Container-as-a-Service| Kubernetes), CaaS Governance (HELM) Digital Product UX/UI/LCNC (PWA/Micro frontend/ Low Code No Code canvass/ Self Service Interface) Distributed Computing Cybersecurity Industry 4.0 (IIoT, Intelligent Operation Platform, OT & IT) Blockchain in Data Trust Data & Digital Transformation
As per, Statista Digital Economy Compass 2019, two major trends will disrupt the economy and our lives: • Data-driven world, which is linked to the exponentially-growing amount of digitally-collected data. • The increasing importance of Artificial Intelligence / Machine Learning / Data Science, which derives insights from this tremendous amount of data.
For the sake of consistency, we will use the term machine learning (ML), however, the concepts apply to both artificial intelligence and data science fields. Every machine learning pipeline is a set of operations, which are executed to produce a model. An ML model is roughly defined as a mathematical representation of a real-world process. We might think of the ML model as a function that takes some input data and produces an output (classification, sentiment, recommendation, or clusters). The performance of each model is evaluated by using evaluation metrics, such as precision & recall, or accuracy.
The ML Deployment Gap
More and more enterprises are experimenting with ML. Getting a model into the real world involves more than just building it. In order to take full advantage of the built ML model by making it available to our core software system, we would need to incorporate the trained ML model into the core codebase. That means, we need to deploy the ML model into production. By deploying models, other software systems can supply data to these and get predictions, which are in turn populated back into the software systems. Therefore, the full advantage of ML models is only possible through the ML model deployment. However, according to a report by Algorithmia“2020 State of Enterprise Machine Learning” , many companies haven’t figured out how to achieve their ML/AI goals. Because bridging the gap between ML model building and practical deployments is still a challenging task. There’s a fundamental difference between building a ML model in the Jupyter notebook model and deploying an ML model into a production system that generates business value. Although AI budgets are on the rise, only 22 percent of companies that use machine learning have successfully deployed an ML model into production.
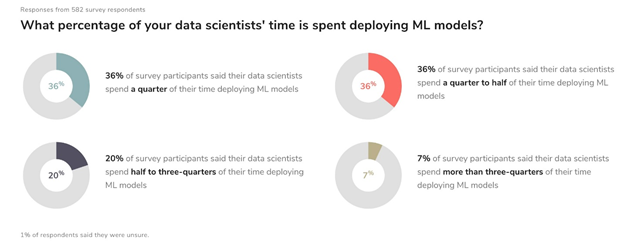
The “2020 State of Enterprise Machine Learning” report is based on a survey of nearly 750 people including machine learning practitioners, managers for machine learning projects, and executives at tech firms. Half of the respondents answered that it takes their company between a week and three months to deploy an ML model. About 18 percent stated that it takes from three months to a year. According to the report “The main challenges people face when developing ML capabilities are scale, version control, model reproducibility, and aligning stakeholders”.
The ML Scenarios Change that Need to be Managed
The reason for the previously described deployment gap is that the development of the machine learning-based applications is fundamentally different from the development of the traditional software. The complete development pipeline includes three levels of change: Data, ML Model, and Code. This means that in machine learning-based systems, the trigger for a build might be the combination of a code change, data change, or model change. This is also known as“Changing Anything Changes Everything” principle.
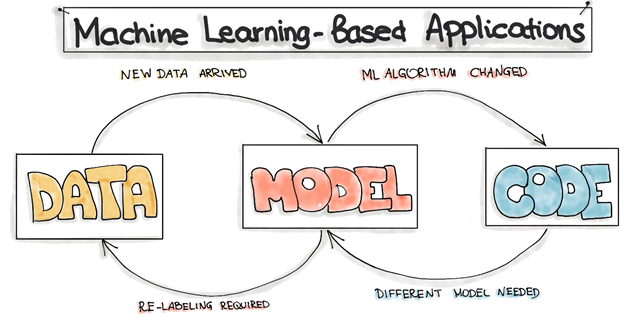
In the following, we list some scenarios of possible changes in machine learning applications:
• After deploying the ML model into a software system, we might recognize that as time goes by, the model starts to decay and to behave abnormally, so we would need new data to re-train our ML model. • After examining the available data, we might recognize that it’s difficult to get the data needed to solve the problem we previously defined, so we would need to re-formulate the problem. • In the ML project at some stages, we might go back in the process and either collect more data, or collect different data and re-label training data. This should trigger the re-training of the ML Model. • After serving the model to the end-users, we might recognize that the assumptions we made for training the model are wrong, so we have to change our model. • Sometimes the business objective might change while project development and we decide to change the machine learning algorithm to train the model.
Additionally, three common issues influence the value of ML models once they’re in production. The first is data quality: since ML models are built on data, they are sensitive to the semantics, amount and completeness of incoming data.
The second is model decay: the performance of ML models in production degenerate over time because of changes in the real-life data that has not been seen during the model training.
The third is locality: when transferring ML models to new business customers, these models, which have been pre-trained on different user demographics, might not work correctly according to quality metrics.
MLOps by definition
MLOps is a set of practices for collaboration and communication between data scientists and operations professionals. Applying these practices increases the quality, simplifies the management process, and automates the deployment of Machine Learning and Deep Learning models in large-scale production environments. It’s easier to align models with business needs, as well as regulatory requirements.
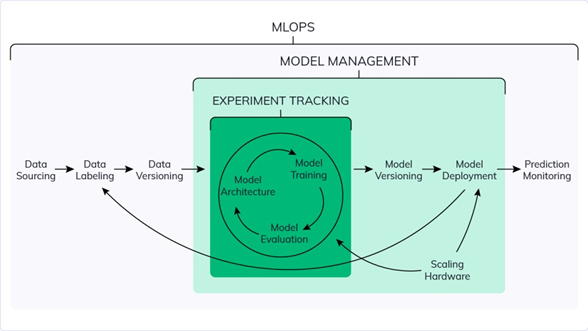
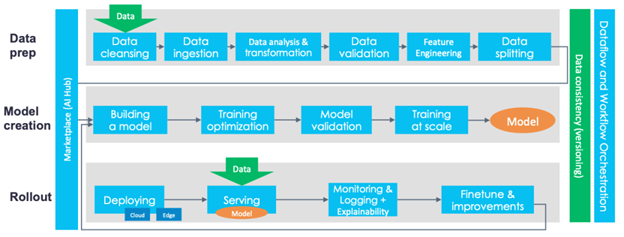
MLOps is slowly evolving into an independent approach to ML lifecycle management. It applies to the entire lifecycle – data gathering, model creation (software development lifecycle, continuous integration/continuous delivery), orchestration, deployment, health, diagnostics, governance, and business metrics. The key phases of MLOps are: • Data gathering • Data analysis • Data transformation/preparation • Model training & development • Model validation • Model serving • Model monitoring • Model re-training
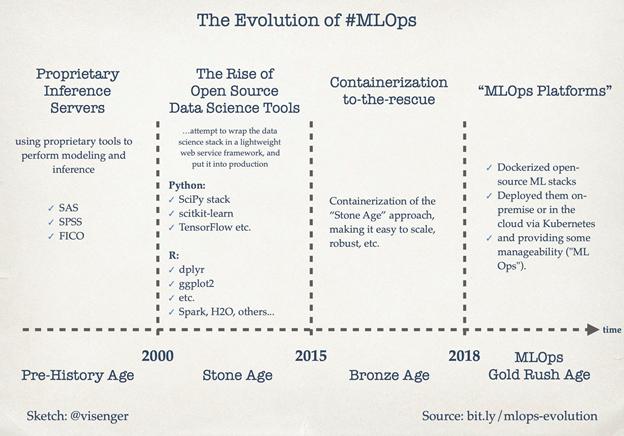
The Evolution of the MLOps
DevOps vs MLOps
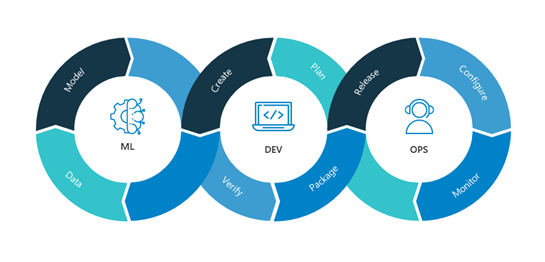
Source: NealAnaltyics
DevOps and MLOps have fundamental similarities because MLOps were derived from DevOps principles. But they’re quite different in execution:
Unlike DevOps, MLOps is much more experimental in nature. Data Scientists and ML/DL engineers have to tweak various features – hyperparameters, parameters, and models – while also keeping track of and managing the data and the code base for reproducible results. Besides all the efforts and tools, the ML/DL industry still struggles with the reproducibility of experiments. This topic is out of the scope of this article, so for more information check the reproducibility subsection in references at the end.
Hybrid team composition: the team needed to build and deploy models in production won’t be composed of software engineers only. In an ML project, the team usually includes data scientists or ML researchers, who focus on exploratory data analysis, model development, and experimentation. They might not be experienced software engineers who can build production-class services.
Testing: testing an ML system involves model validation, model training, and so on – in addition to the conventional code tests, such as unit testing and integration testing.
Automated Deployment: you can’t just deploy an offline-trained ML model as a prediction service. You’ll need a multi-step pipeline to automatically retrain and deploy a model. This pipeline adds complexity because you need to automate the steps that data scientists do manually before deployment to train and validate new models.
Production performance degradation of the system due to evolving data profiles or simply Training-Serving Skew: ML models in production can have reduced performance not only due to suboptimal coding but also due to constantly evolving data profiles. Models can decay in more ways than conventional software systems, and you need to plan for it.
MLOps and DevOps are similar when it comes to continuous integration of source control, unit testing, integration testing, and continuous delivery of the software module or the package. However, in ML there are a few notable differences: • Continuous Integration (CI) is no longer only about testing and validating code and components, but also testing and validating data, data schemas, and models. • Continuous Deployment (CD) is no longer about a single software package or service, but a system (an ML training pipeline) that should automatically deploy another service (model prediction service) or roll back changes from a model. • Continuous Testing (CT) is a new property, unique to ML systems, that’s concerned with automatically retraining and serving the models.
References:
MLOps: What It Is, Why It Matters, and How to Implement It - neptune.ai
What is MLOps — Everything You Must Know to Get Started | by Harshit Tyagi | Towards Data Science
Thank you for joining! Stay connected with the latest updates and insights by visiting my website www.DeepHiveMind.com. Don't forget to follow me on social media for more tech tips and discussions. Let's continue exploring the exciting world of technology together! #TechTalks #StayConnected




