

Lambda Architecture

Here to share my experience in the realm of expertise:
Cloud Adoption Applied AI, ML & MLOps Microservices 2.0 Digital Portfolio & Product P&L Federated Learning (Adv. AI) IaC, X-Ops, Containers, CaaS (Container-as-a-Service| Kubernetes), CaaS Governance (HELM) Digital Product UX/UI/LCNC (PWA/Micro frontend/ Low Code No Code canvass/ Self Service Interface) Distributed Computing Cybersecurity Industry 4.0 (IIoT, Intelligent Operation Platform, OT & IT) Blockchain in Data Trust Data & Digital Transformation
With tremendous rate of growth in the amounts of data, there have been innovations both in storage and processing of big data. According to Dough Laney, Big data can be thought of as an increase in the 3 V’s, i.e. Volume, Variety and Velocity. Due to sources such as IoT sensors, twitter feeds, application logs and database state changes, there has been an inflow of streams of data to store and process. These streams are a flow of continuous and unbounded data that demand near real-time processing of data.
The field of data analytics is growing immensely to draw valuable insights from big chunks of raw data. In order to compute information in a data system, processing frameworks and processing engines are essential. The traditional relational database seems to show limitations when exposed to the colossal chunks of unstructured data. There is a need to decouple compute from storage.
Traditional batch processing of data gives good results but with a high latency. And to achieve results in real-time with low-latency, a good solution is to use Apache Kafka coupled with Apache Spark. This streaming model does wonders in high availability and low latency but might suffer in terms of accuracy. In most of the scenarios, use cases demand both fast results and deep processing of data.
The processing frameworks can be categorized into three frameworks –batch processing, stream data processing and hybrid data processing frameworks. In this blog we mainly focus towards Lambda Architecture that unifies batch and stream processing. Lambda Architecture (LA) describes how LA addressed the need of unifying the benefits of batch and stream processing models. Many tech companies such as Twitter, LinkedIn, Netflix and Amazon use this architecture to solve multiple business requirements.
Lambda Architecture
Commonly known as a software design pattern, the lambda architecture unifies online and batch processing within a single framework. The pattern is suited to applications where there are time delays in data collection and availability through dashboards, requiring data validity for online processing as it arrives. The pattern also allows for batch processing for older data sets to find behavioural patterns as per user needs.
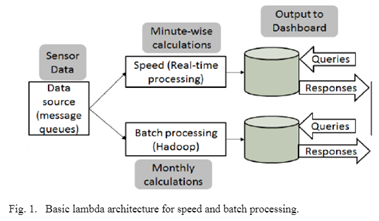
Figure 1 shows the basic architecture of how the lambda architecture works. It caters as three layers (1) Batch processing for precomputing large amounts of data sets (2) Speed or real time computing to minimize latency by doing real time calculations as the data arrives and (3) a layer to respond to queries, interfacing to query and provide the results of the calculations.
Lambda architecture allows users to optimise their costs of data processing by understanding which parts of the data need online or batch processing. The architecture also partitions datasets to allow various kinds of calculation scripts to be executed on them.
* Batch layer*
New data keeps coming as a feed to the data system. At every instance it is fed to the batch layer and speed layer simultaneously. Any new data stream that comes to batch layer of the data system is computed and processed on top of a Data Lake. When data gets stored in the data lake using databases such as in memory databases or long term persistent one like NoSQL based storages batch layer uses it to process the data using MapReduce or utilizing machine-learning (ML) to make predictions for the upcoming batch views.
* Speed Layer (Stream Layer)*
The speed layer uses the fruit of event sourcing done at the batch layer. The data streams processed in the batch layer result in updating delta process or MapReduce or machine learning model which is further used by the stream layer to process the new data fed to it. Speed layer provides the outputs on the basis enrichment process and supports the serving layer to reduce the latency in responding the queries. As obvious from its name the speed layer has low latency because it deals with the real time data only and has less computational load.
* Serving Layer*
The outputs from batch layer in the form of batch views and from speed layer in the form of near-real time views are forwarded to the serving layer which uses this data to cater the pending queries on ad-hoc basis.
Here is a basic diagram Figure2 of what Lambda Architecture model would look like:
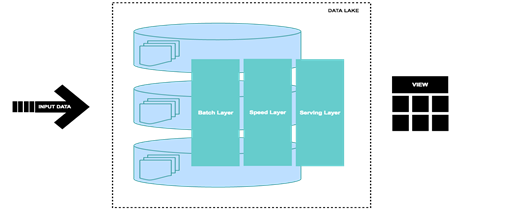
Figure 2: Basic Lambda Architecture
Applications of Lambda Architecture
Lambda architecture can be deployed for those data processing enterprise models where:
User queries are required to be served on ad-hoc basis using the immutable data storage.
Quick responses are required and system should be capable of handling various updates in the form of new data streams.
None of the stored records shall be erased and it should allow addition of updates and new data to the database.
Limitations of the Traditional Lambda Architecture
Initially, when the LA was proposed, the batch layer was meant to be a combination of Hadoop File System and MapReduce and the stream layer was realized using Apache Storm. Also, the serving layer was a combination of two independent databases i.e. ElephantDB and Cassandra. Inherently, this model had a lot of implementation and maintenance issues. [4] Developers were required to possess a good understanding of two different systems and there was a steep learning curve.
Additionally, creating a unified solution was possible but resulted a lot of merge issues, debugging problems and operational complexity. The incoming data needs to be fed to both the batch and the speed layer of the LA. It is very important to preserve the ordering of events of the input data to obtain thorough results.
The LA does not always live up to the expectation and many industries use full batch processing system or a stream processing system to meet their use case.
A Proposed Solution
As understood, the LA can lead to code complexity, debugging and maintenance problems if not implemented in the right manner. A proper analysis and understanding of existing tools helped me realize that the LA can be implemented using a technology stack comprising of Apache Kafka, Apache Spark and Apache Cassandra. There are multiple ways of building a LA.
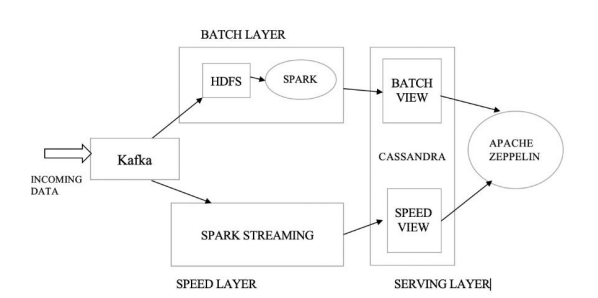
Key Highlights:
The trouble and overhead to duplicate incoming data can be eliminated with the help of Kafka. Kafka can store messages over a period of time that can be consumed by multiple consumers. Each consumer maintains an offset to denote a position in the commit log. Thus, the batch and speed layers of the LA can act as consumers to the published records on the topics in Kafka. This reduces the duplication complexity and simplifies the architecture.
Spark’s rich APIs for batch and streaming make it a tailor-made solution for the LA. The underlying element for Spark streaming API (D Streams) is a collection of RDDs. Hence, there is huge scope for code reuse. Also, the business logic is simpler to maintain and debug. Additionally, for the batch layer, Spark is a better option due to the speed it achieves because of in-memory processing
Kafka is a beast that can store messages for as long as the use case demands (7 days by default, but that is configurable). We have used HDFS for reliability in case of human or machine faults. In fact, we can totally eliminate HDFS from the batch layer and store the records as they are in the Kafka topics. Whenever re-computation is required, the commit log inside Kafka can be replayed
Kafka’s commit log is very useful for event sourcing as well. As the commit log is an immutable, append-only data store, a history of user events can be tracked for analytics. It finds it application in online retail and recommendation engines.
Cassandra is a write heavy database that can build tables as per new use cases. Kafka commit log can be replayed and new views can be materialized using Cassandra
References:
Thank you for joining! Stay connected with the latest updates and insights by visiting my website www.DeepHiveMind.com. Don't forget to follow me on social media for more tech tips and discussions. Let's continue exploring the exciting world of technology together! #TechTalks #StayConnected




