

DataOps - A Brief Introduction

Here to share my experience in the realm of expertise:
Cloud Adoption Applied AI, ML & MLOps Microservices 2.0 Digital Portfolio & Product P&L Federated Learning (Adv. AI) IaC, X-Ops, Containers, CaaS (Container-as-a-Service| Kubernetes), CaaS Governance (HELM) Digital Product UX/UI/LCNC (PWA/Micro frontend/ Low Code No Code canvass/ Self Service Interface) Distributed Computing Cybersecurity Industry 4.0 (IIoT, Intelligent Operation Platform, OT & IT) Blockchain in Data Trust Data & Digital Transformation
Organisations want to accelerate their transformation, but data and infrastructure complexity slow them down. Disparate software and hardware, manual processes and organisational silos result in a piecemeal approach and a cascade of fragmentation, operational inefficiency and business risk – all at the expense of agility and innovation.
Inspired by the DevOps movement, the DataOps strategy strives to speed the production of applications running on big data processing frameworks. Additionally, DataOps seeks to break down silos across IT operations and software development teams, encouraging line-of-business stakeholders to also work with data engineers, data scientists and analysts. This helps to ensure that the organization’s data can be used in the most flexible, effective manner possible to achieve positive business outcomes.
DevOps in comparison:
DevOps is an approach to software development that accelerates the build lifecycle (formerly known as release engineering) using automation. DevOps focuses on continuous deployment of software by leveraging on-demand IT resources and by automating integration, test, and deployment of code. This merging of software development (“dev”) and IT operations (“ops”) reduces time to deployment, decreases time to market, minimizes defects, and shortens the time required to resolve issues.
Using DevOps, leading companies have been able to reduce their software release cycle time from months to literally seconds. This breakthrough enabled them to grow and lead in fast-paced, emerging markets. Companies like Google, Amazon, and many others now release software many times per day. By improving the quality and cycle time of code releases, DevOps deserves a lot of credit for these companies’ success.
DataOps by definition is an Agile approach to designing, implementing and maintaining a distributed data architecture that will support a wide range of open source tools and frameworks in production. The goal of DataOps is to create business value from big data. DataOps promises to take the pain out of managing data for reporting and analytics. In most companies, data travels a tortuous route from source systems to business users. Behind the scenes, data professionals go through gyrations to extract, ingest, move, clean, format, integrate, transform, calculate, and aggregate data before releasing it to the business community. These “data pipelines” are inefficient and error prone: data hops across multiple systems and is processed by various software programs. Humans intervene to apply manual workarounds to fix recalcitrant transaction data that was never designed to be combined, aggregated, and analyzed by knowledge workers. Reuse and automation are scarce. Business users wait months for data sets or reports. The hidden costs of data operations are immense.
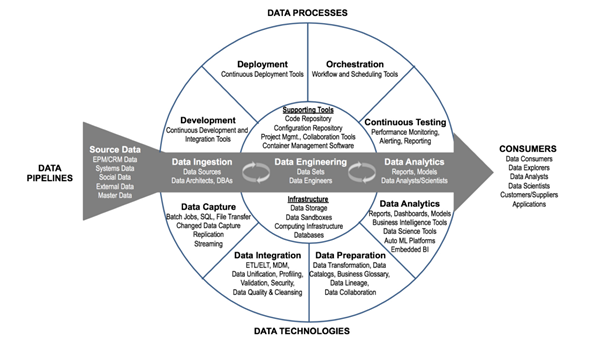
Figure 1: DataOps Technical Framework
DataOps promises to streamline the process of building, changing, and managing data pipelines. Its primary goal is to maximize the business value of data and improve customer satisfaction. It does this by speeding up the delivery of data and analytic output, while simultaneously reducing data defects—essentially fulfilling the mantra “better, faster, cheaper.”
DataOps emphasizes collaboration, reuse, and automation, along with a heavy dose of testing and monitoring. It employs team-based development tools for creating, deploying, and managing data pipelines. This report explains what DataOps is, where it came from, what it promises, and how to apply it successfully.
**Key Takeaways **
DataOps applies the rigor of software engineering to data development.
DataOps practices borrow from DevOps, Agile, Lean, and Total Quality Management (TQM) methodologies.
DataOps makes it possible to scale development and increase the output of data teams while simultaneously improving the quality of data output.
The core mantras of DataOps are: faster, better, cheaper; collaborate, iterate, automate; and standardize, reuse, refine.
DataOps requires a culture of continuous improvement.
Dimensions of DataOps
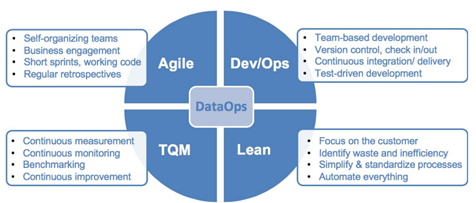
Figure 2: Dimensions of DataOps
DataOps means different things to different teams. Some embrace agile concepts and methods, while others implement DevOps tools to better streamline and govern development processes. Others focus on testing to improve quality and create a “lights out” data operating environment. However, once teams experience the benefits of DataOps, they often embrace the complete package of DataOps techniques and tools to deliver faster, better, cheaper data products.
For example, the data team at Northwestern Medicine, DataOps first meant creating agile, crossfunctional teams dedicated to individual business groups. Each agile team consists of a data architect, a data engineer, a report developer, and a business representative (i.e., product manager), who are cross-trained in each other’s skills (except the business person). The team consolidates and prioritizes requests and building end-to-end solutions for their client in an incremental fashion. Says Akhter, “This approach has improved customer satisfaction. There is greater communication and transparency, and the teams have delivered a series of quick wins.”
To increase team productivity, Northwestern Medicine invested in a number of tools to foster collaboration and automation. To increase team productivity, Northwestern Medicine invested in a number of tools to foster collaboration and automation. The data teams now use Git as a source control repository for data integration code; Jira to coordinate Scrum processes and manage user stories; TeamCity to facilitate code integration in a team-based development environment; and Octopus to deploy code from test into production. “Historically, data teams have been loose in how they build things,” says Akhter. “We now follow DataOps principles where we segregate duties and environments and apply automation wherever possible.”
When you need DataOps:
Most data teams can benefit from DataOps, some more than others. If there is “data pain,” DataOps can help. Following is a list of symptoms that indicate whether your data team is a good candidate for DataOps.
Your data team is flooded with minor request tickets and is burning out
Business users don’t trust the data because it contains too many errors
You are too busy putting out “data fires” to implement predictive analytics
Source system changes keep breaking your data integration jobs and data pipelines
Business users don’t understand why it takes so long to get a new data set
You have difficulty meeting service level agreements (SLAs) for critical applications
It takes months to deploy a new analytics use case
You rely on business users to debug data quality issues, much to their dismay
Data analysts recreate existing data pipelines with minor variations
Data scientists wait for months for data and computing resources
It is difficult to migrate to the cloud because your data environment is too complex
Your self-service initiative has spawned hundreds of data silos
Your data lake is more of a data swamp
It takes months to deploy a single predictive model
Benefits of DataOps
Transitioning to a DataOps strategy can bring an organization the following benefits:
Provides real-time data insights
Reduces cycle time of data science applications
Enables better communication and collaboration between teams and team members
Increases transparency by using data analytics to predict all possible scenarios
Processes are built to be reproducible and reuse code whenever possible
Ensures higher data quality.
Creates a unified, interoperable data hub.
Thank you for joining! Stay connected with the latest updates and insights by visiting my website www.DeepHiveMind.com. Don't forget to follow me on social media for more tech tips and discussions. Let's continue exploring the exciting world of technology together! #TechTalks #StayConnected




