

Data Mesh - Domain Driven Goal and Principles
Here to share my experience in the realm of expertise:
Cloud Adoption Applied AI, ML & MLOps Microservices 2.0 Digital Portfolio & Product P&L Federated Learning (Adv. AI) IaC, X-Ops, Containers, CaaS (Container-as-a-Service| Kubernetes), CaaS Governance (HELM) Digital Product UX/UI/LCNC (PWA/Micro frontend/ Low Code No Code canvass/ Self Service Interface) Distributed Computing Cybersecurity Industry 4.0 (IIoT, Intelligent Operation Platform, OT & IT) Blockchain in Data Trust Data & Digital Transformation
The Domain-driven Goal of DATA MESH
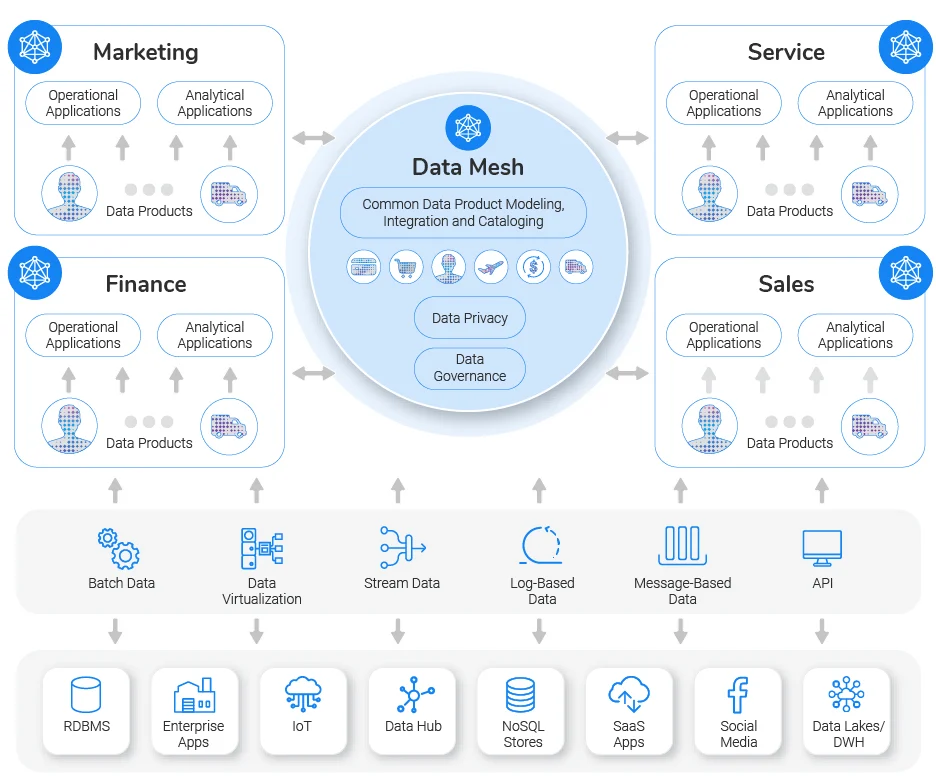
Distributed Data Mesh, which allows DOMAIN-SPECIFIC data and treats “DATA-as-a-PRODUCT”.
💡 Enabling each DOMAIN to handle its own DATA-PIPELINES. This is different from plumbing data from the traditional (monolithic) platforms that generally tightly couple and often slow down the ingestion, storage, transformation, and consumption of data from one central data lake or hub.
💡 Therefore, Data Mesh paradigm objective is to reduce overall friction for information flow in the organization, where the data producer is responsible for the datasets they produce and is accountable to the consumer based on the advertised SLAs.
Move away from tightly coupled data interfaces and varying data flows towards an architecture that allows eco-system connectivity.
To be an integral part of Data Mesh OSS Community, Please be conversant with Data Mesh as defined by Martin Fowler
Why DATA MESH Architecture/Model/Paradigm?
DRIVERS OF DATA MESH
Let us explore Why to move away from 'CENTERAL DATA PLATFORM' Architectue to 'DATA MESH Paradigm based DATA PLATFORM' (Decentralized Domain Oriented Data Product, powered by Topologies for Decentralized Data-Product Node governance with Self-serve Data Infra)?
Answer of the aforementioned Question lies is in 3 STEP PROCESS - - STEP 1: Let's first acknowledge {The Beauty of 'Central Data Platform'} - STEP 2: Let's then explore { The Challenge/ Bottleneck with 'Central Data Platform' } - STEP 3: Let's then find out solution in { 'Data Mesh as Solution'}
STEP 1: The Beauty of 'Central Data Platform':
Organizations of all sizes have recognized that data is one of the key enablers to increase and sustain innovation, and drive value for their customers and business units. They are eagerly modernizing traditional data platforms with cloud-native technologies that are highly scalable, feature-rich, and cost-effective. A centralized model is intended to [a] simplify staffing and training by centralizing data and technical expertise in a single place, [b] to reduce technical debt by managing a single data platform, and [c] to reduce operational costs.
STEP 2: The Challenge/ Bottleneck with 'Central Data Platform': Managing data through a Central Data Platform can create following multi-dimensional challenges, (as central teams may not understand the specific needs of a data domain, whether due to data types and storage, security, data catalog requirements, or specific technologies needed for data processing.) --
[a] scaling, [b] ownership, [c] accountability challenges, [d] Huge backlog - 'Central Data platform' pattern works for smaller organizations and organizations that have a high degree of centralization from a team setup perspective. However, using only a single team often creates a bottleneck in larger organizations. This bottleneck causes a huge backlog, with parts of an organization having to wait for data integration services and Analytical solutions. [e] Organizations adopting MODERN DATA SCIENCE solutions - Many modern data science solutions require more data than traditional business intelligence solutions did in the past. It creates a huge backlog and depedencies on central Data platform team. [f] Organizations are DECENTRALIZED and DISTRIBUTED from a business perspective - Most organizations are decentralized and distributed from a business perspective. Having a single team handling all of data ingestion on a single platform in a large organization can also be problematic. One team rarely has experts for every data source. [g] Microservices as an Application development pattern for Business Transcation Processing Source System -- The recent switch to using microservices as an application development pattern is another driver of long backlogs around data integration because it increases the number of data sources.
STEP 3: 'Data Mesh as Solution':
These challenges can often be reduced by giving ownership and autonomy to the team who owns the data, best allowing them to build data products, rather than only being able to use a common central data platform. Data Mesh paradigm is the solution as it supports all the constructs to make it work. As
💡 For instance, product teams (in E-Commerce/ e-shop) are responsible for ensuring the product inventory is updated regularly with new products and changes to existing ones. They’re the domain experts of the product inventory datasets. If a discrepancy occurs, they’re the only group who knows how to fix it. 💡 Therefore, they’re best candidates to implement and operate a technical solution to ingest, process, and produce the product inventory dataset. Data Mesh paradigm and Architecture enables the domain team to perform and own these activities.
💡 With the Data Mesh, The E-Commerce/e-shop 'product team' owns everything leading up to the data being consumed: they choose the technology stack, operate in the mindset of data as a product, enforce security and auditing, and provide a mechanism to expose the data to the organization in an easy-to-consume way.
💡 Data MESH paradigm is based on Architectural framework which infuses Microservices as an application development pattern for the MODERN DISTRIBUTED DECNETRALIZED DATA PLATFORM.
💡 Therefore, Data Mesh paradigm reduces overall friction for information flow in the organization, where the data producer is responsible for the datasets they produce and is accountable to the consumer based on the advertised SLAs.
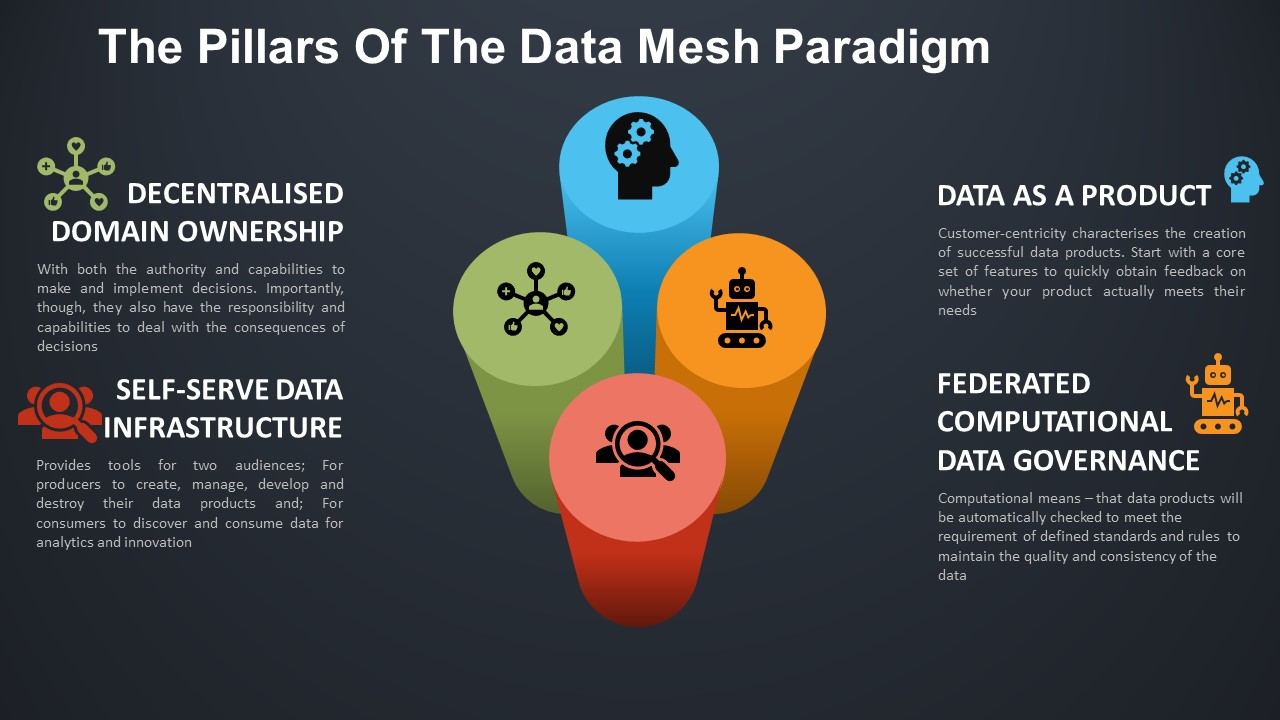
Principles of Enterprise Data MESH
Data Mesh as defined by Martin Fowler is a new paradigm to DOMAIN-ORIENTED + DATA PRODUCT + SELF-SERVE DATA Infra + DECENTRALIZED TOPOLOGY data architecture that conforms to the following main Architecture Principles, such as:
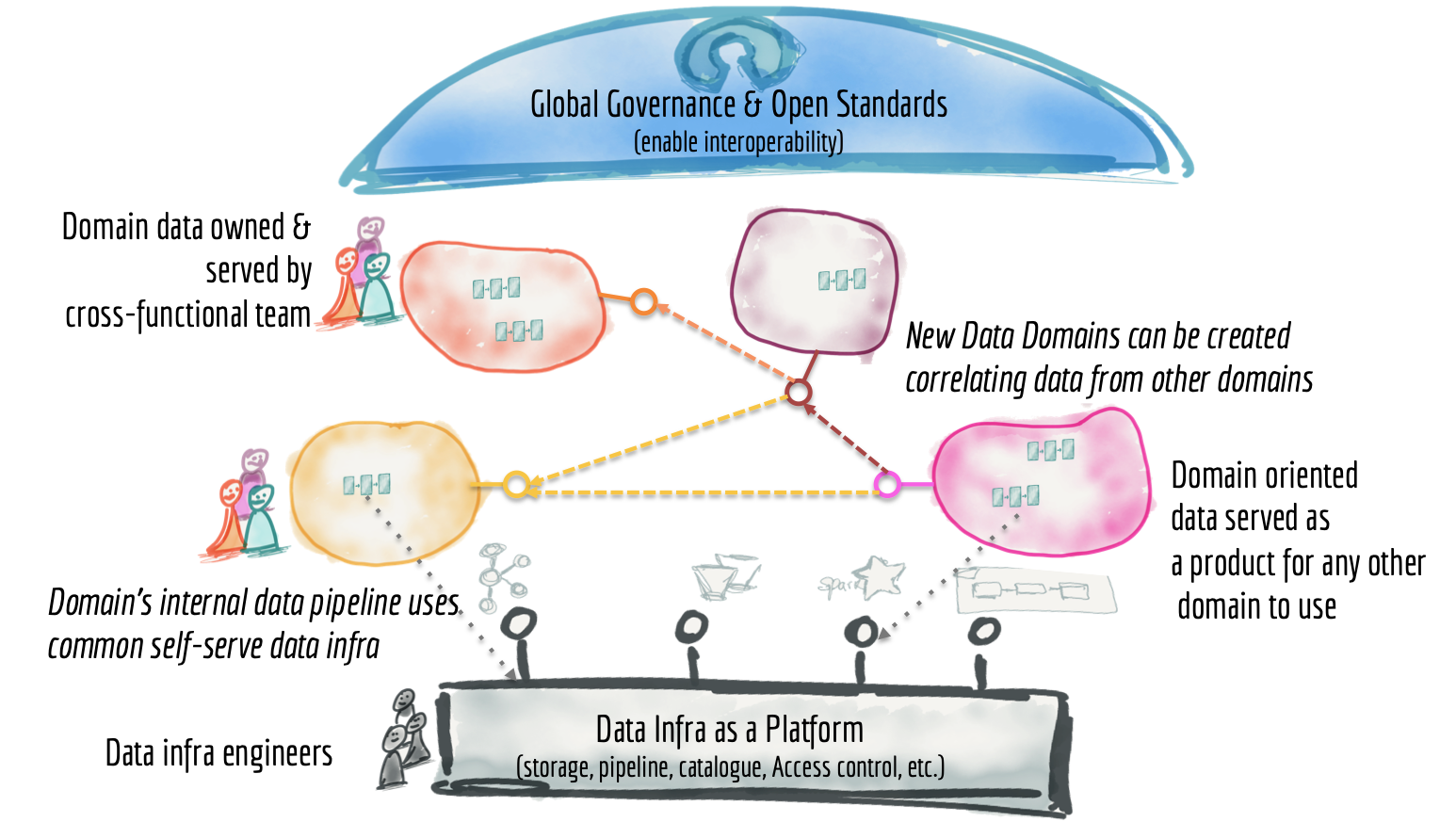
Domain Oriented DECENTRALIZATION a. Domain-oriented Data compute
b. Domain-oriented Data Stoarge
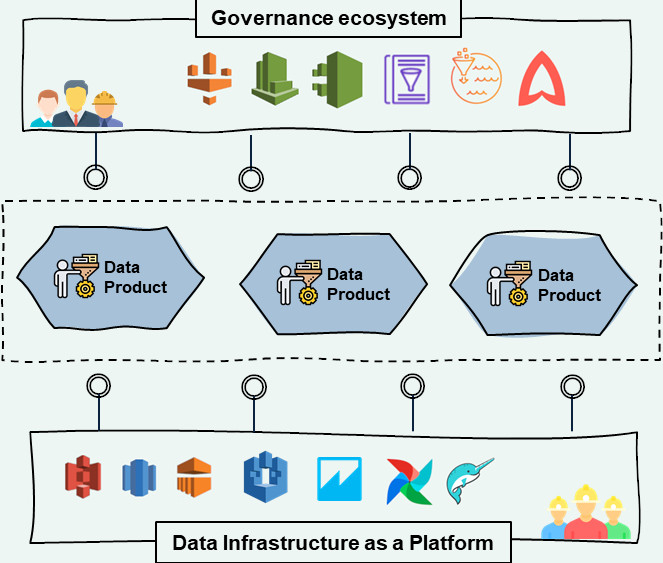
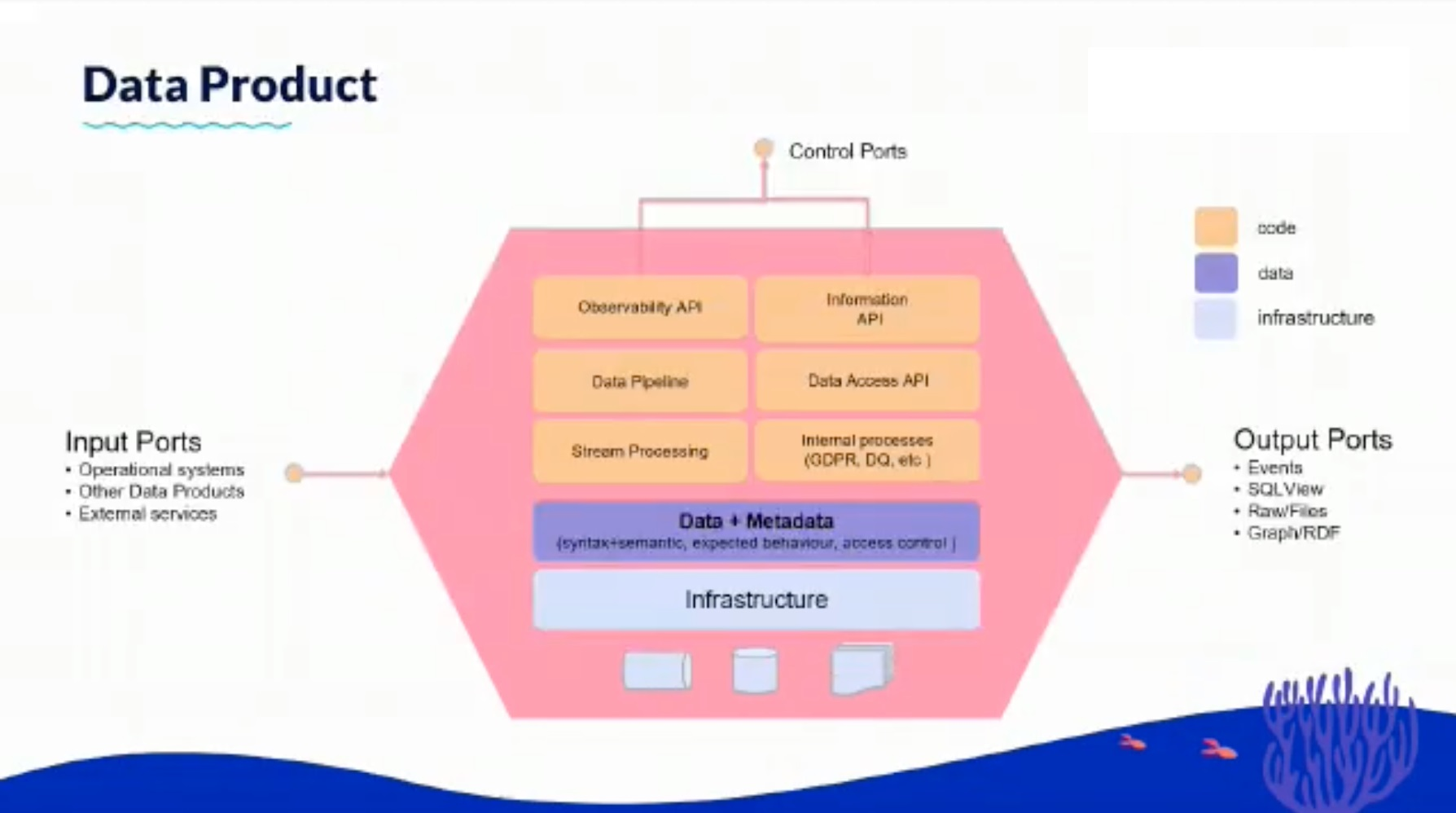
c. Domain-oriented Data pipeline d. Domain-oriented Data ModelData-as-a-Product DATA PRODUCT is a function of Data platform governed by MICROSERVICE GOVERNANCE & SERVICE MESH for self-discoverable, resilient, secured and performant for data domain services
Caveat: DATA PRODUCT & SERVICES are not defined by the size of the function, but instead by the context, cohesion and coupling, requiring either orchestration (Service) or choreography (Micro-Service) to mediate between Services
Self-serve Infra for data platform (DataInfra-as-a-Service)
Centeralized Data Governance (Federated Computational Governance) a. Centralized Data Provenance (Domain Data Data catalogue, Data Protection and PII Anonymization, Data Lineage, Enterprise MDM 360, et al)
b. Unified Policy Management
c. Unified Data Virtualization Service
d. Federated Data Access Control Service
e. Organization wide Secured Data SharingDATA MESH Topology (DECENTRALIZED Topology to power DataMesh NODE PATTERN) a. Governed Data Mesh topology
b. Harmonized Data Mesh topology
c. Highly federated Data Mesh topology
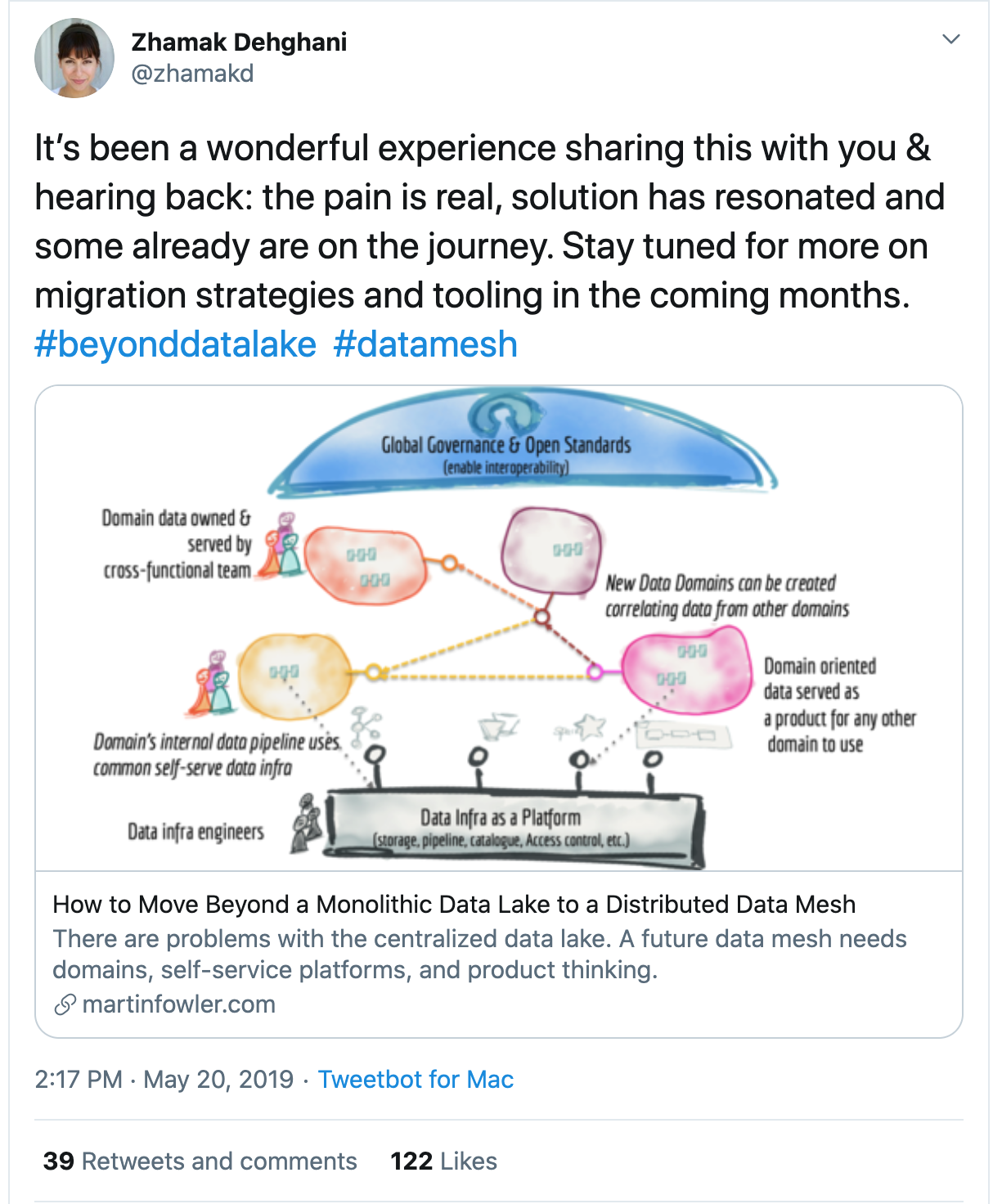


Based on the aforementioned tenets of Data Mesh, it's safe to call out that,
"Data Mesh is a MESH OF DATA PRODUCT NODES".
Pretty much alike "Service MESH of Microservices powered Data Products".
Thank you for joining! Stay connected with the latest updates and insights by visiting my website www.DeepHiveMind.com. Don't forget to follow me on social media for more tech tips and discussions. Let's continue exploring the exciting world of technology together! #TechTalks #StayConnected




