

Knowledge Retrieval System – powered by Generative AI model
Here to share my experience in the realm of expertise:
Cloud Adoption Applied AI, ML & MLOps Microservices 2.0 Digital Portfolio & Product P&L Federated Learning (Adv. AI) IaC, X-Ops, Containers, CaaS (Container-as-a-Service| Kubernetes), CaaS Governance (HELM) Digital Product UX/UI/LCNC (PWA/Micro frontend/ Low Code No Code canvass/ Self Service Interface) Distributed Computing Cybersecurity Industry 4.0 (IIoT, Intelligent Operation Platform, OT & IT) Blockchain in Data Trust Data & Digital Transformation
Overview
Knowledge Retrieval Systems, which can be called Q&A systems, are software applications designed to automatically generate responses to user questions or queries. These applications have a wide range of uses and are employed in various domains. The earliest Q&A systems were rule-based and used predefined rules and templates. Early web search engines like Yahoo! and AltaVista allowed users to enter keyword queries to find relevant information.

Around 2010, Deep learning, particularly the use of neural networks, revolutionized NLP and Q&A systems. Recent advancements have focused on making Q&A bots more conversational, enabling multi-turn interactions. Chatbots like OpenAI's GPT-3 and GPT-4 can engage in extended dialogues and answer follow-up questions more coherently. Q&A applications leverage natural language processing (NLP), machine learning, and knowledge representation techniques to understand and generate human-like responses to a wide range of questions, making them versatile tools in today's digital landscape.
RAG:
Retrieval augmented generation (RAG) is a natural language processing (NLP) technique that combines the strengths of both retrieval- and generative-based artificial intelligence (AI) models. RAG AI can deliver accurate results that make the most of pre-existing knowledge but can also process and consolidate that knowledge to create unique, context-aware answers, instructions, or explanations in human-like language rather than just summarizing the retrieved data. RAG AI is different from generative AI in that it is a superset of generative AI.
Why RAG is important?
- Privacy Preservation:
Localized Retrieval: RAG allows for localized retrieval of relevant information from private data without the need to share the entire dataset. The retrieval step can be performed on the user's private data, preserving sensitive information.
- Data Confidentiality:
No Sharing of Raw Data: RAG operates by retrieving relevant passages or documents without sharing the raw data itself. This is crucial in situations where the data contains sensitive or proprietary information that cannot be exposed.
- Computational Efficiency:
Reduced Computational Load: By leveraging retrieval to narrow down the search space before applying generative models, RAG can reduce the computational load compared to models that generate answers without a retrieval step. This is beneficial when working with limited computing resources.
- Customization for Specific Domains:
Domain-Specific Retrieval: RAG allows for the incorporation of domain-specific retrieval methods, tailoring the QA system to specific contexts or industries. This is advantageous when dealing with specialized or proprietary datasets. Now let’s see some industry use cases of the Q&A system.
Industry Use-cases of Custom Knowledge Retrieval System
As new and creative use cases for this technology develop, many sectors should use custom question-answering solutions. Examining some of these usage cases.
Manufacturing Industry
Q&A bots can be valuable tools in the manufacturing industry, helping streamline operations, enhance productivity, and improve decision-making.
Maintenance and Troubleshooting: Q&A bots can assist maintenance teams by providing quick answers to common equipment issues and troubleshooting procedures. Technicians can access information on the spot, reducing downtime and improving machinery efficiency.
Quality Control: Q&A bots can assist quality control inspectors by guiding inspection criteria and standards. They can also answer questions related to quality control procedures and help ensure that products meet specified quality standards.
Healthcare Industry
For patients to receive timely treatment for some conditions, the knowledge is essential. Without the need for a live human, healthcare organizations can create an interactive chatbot or Q&A application that can deliver medical information, pharmacological information, symptom descriptions, and treatment recommendations in natural language.
Legal Industry
To resolve court matters, lawyers work with enormous amounts of legal knowledge and paperwork. Lawyers can be more productive and resolve cases much more quickly with the use of custom LLM programs created using such massive volumes of data.
Customer Support Assistance
With the emergence of LLMs, the transformation in customer assistance has started. Customer service bots created on a company's papers can assist customers in making quicker and more educated decisions, increasing revenue, whether the business is E-commerce, telecommunications, or finance.
Technology Industry
Programming assistance is the most revolutionary application of Q&A software. To assist programmers in problem-solving, comprehending code syntax, troubleshooting issues, and implementing certain functions, tech corporations can create such apps on their code base.
Government and Public Services
Many people may be overwhelmed by the amount of information contained in government regulations and programs. By creating custom applications for such government services, citizens can access information on policies and programs. Additionally, it can aid in appropriately completing applications and forms for the government.
Building Custom Knowledge Retrieval System Using LLM and Vector Database
Introduction
In today's information-driven world, the ability to extract meaningful insights and knowledge from vast amounts of data is paramount. Knowledge Retrieval Systems represent a ground-breaking advancement in the field of artificial intelligence and natural language processing, empowering users to obtain precise and contextually relevant answers to their questions from unstructured textual data.
LLMs are trained using generic information that is readily accessible, therefore the end user may not always find their responses to be precise or helpful. This problem can be resolved by using frameworks like LangChain to create personalized chatbots that give precise responses based on our data. Learn how to create unique Q&A applications and deploy them on the Streamlit Cloud in this post.
What is Lang Chain?
A framework called LangChain makes it easier to create applications utilizing large language models (LLMs). As a framework for language model integration, LangChain's use- cases—which include document analysis and summarization, chatbots, and code analysis—largely correspond to those of language models as a whole.
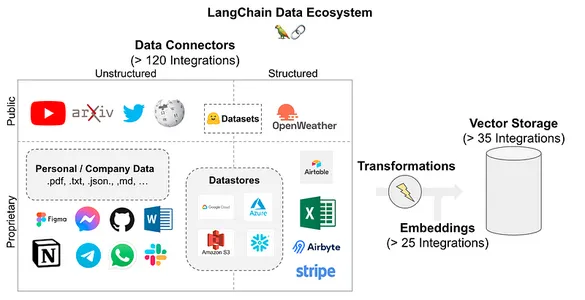
Ref: Source
What is a Vector Database?
A vector database, in the context of computer science and data management, is a type of database system that is designed to store and query vector data efficiently. Vector data typically represents geometric objects or spatial information and is commonly used in geographic information systems (GIS), computer graphics, and machine learning applications.

Vector databases can be used in chatbots to enhance their functionality and improve user experiences in several ways:
Semantic Understanding: Vector databases enable chatbots to store and retrieve semantic representations of user queries, allowing for better comprehension and more accurate responses.
Contextual Memory: They help chatbots remember and recall previous interactions with users, creating a more context-rich conversation that feels personalized and engaging.
Quick Response Times: Vector databases can accelerate query processing, resulting in faster response times for chatbots, which is crucial for providing real-time and seamless interactions.
Recommendation Systems: Chatbots can utilize vector databases to power recommendation engines, suggesting products, services, or content based on user preferences and behaviour.
Multilingual Support: Vector representations can assist chatbots in handling multiple languages by mapping language-specific nuances to a common vector space, enabling effective cross-lingual communication.
Chroma DB:
Chroma Vector Database, is a widely utilized vector database in the development of applications powered by LLM (Large Language Models). Specifically designed for LLM-based applications, Chroma DB is optimized for efficient storage and retrieval of numerous vectors, ensuring low latency and contributing to the creation of user-friendly applications.

Chroma DB is an open-source vector store used for storing and retrieving vector embeddings. Its main use is to save embeddings along with metadata to be used later by large language models. Additionally, it can also be used for semantic search engines over text data.
Chroma Vector Database is a widely utilized vector database in the development of applications powered by LLM (Large Language Models). Specifically designed for LLM-based applications, Chroma DB is optimized for efficient storage and retrieval of numerous vectors, ensuring low latency and contributing to the creation of user-friendly applications. Chroma DB is an open-source vector store used for storing and retrieving vector embeddings. Its main use is to save embeddings along with metadata to be used later by large language models. Additionally, it can also be used for semantic search engines over text data.
Chroma DB key features:
Supports different underlying storage options like DuckDB for standalone or ClickHouse for scalability.
Provides SDKs for Python and JavaScript/TypeScript.
Focuses on simplicity, speed, and enabling analysis.
Building a Semantic Search Pipeline Using OpenAI LLM and Chroma Vector Database
Installing Required Libraries
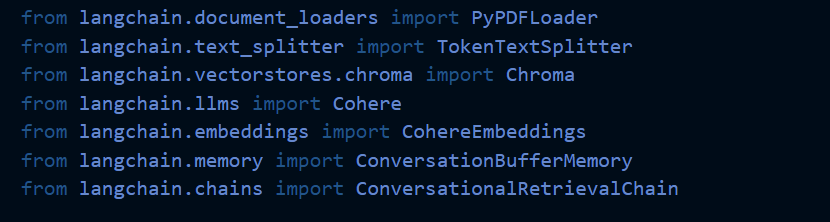
Let’s create a Chroma vector database for our Knowledge Retrieval System
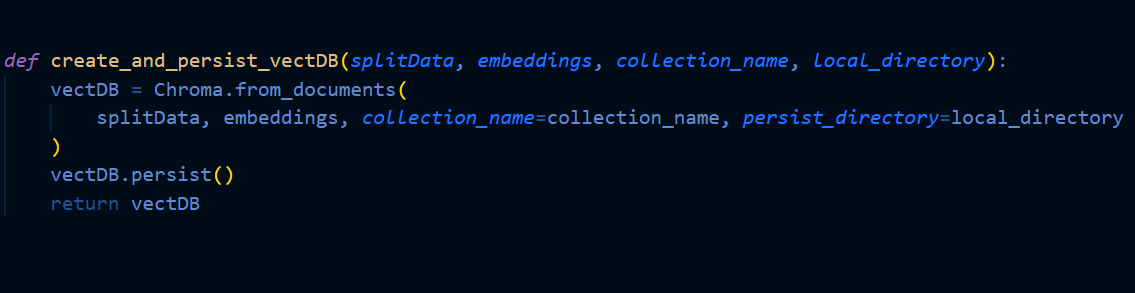
To initialize a vector database in a project environment, install the Chroma DB client in the example above. Establish an index with the necessary dimension and metric to insert vector embeddings into the vector database after the vector database has been started. Build a semantic search pipeline for the application in the next part using Chroma DB and LangChain.
Load the Documents
In this step, load the documents from the directory as a starting point for the AI project pipeline. There are 2 documents in the directory, which load into the project environment.
Split the Texts Data
Text embeddings and LLMs perform better if each document has a fixed length. Thus, Splitting texts into equal lengths of chunks is necessary for any LLM use case. Using ‘RecursiveCharacterTextSplitter’ to convert documents into the same size as text documents.
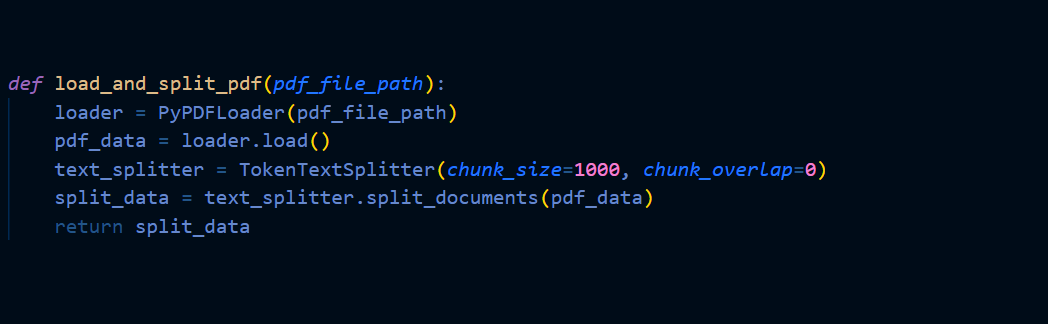
Retrieve Data from the Vector Database
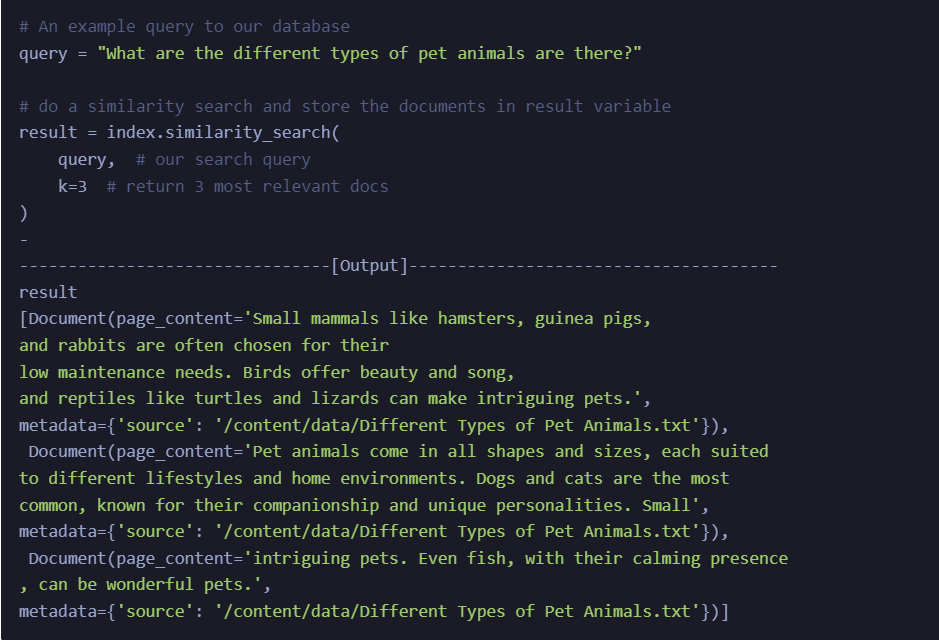
Retrieve the documents at this stage using a semantic search from the vector database. Vectors are stored in an index called “langchain-project” and on querying to the same as below, get most similar documents from the database.
Custom Question Answering Application with Streamlit
In the final stage of the question-answering application, we will integrate every workflow component to build a custom Q&A application that allows users to input various data sources like web-based articles, PDFs, CSVs, etc., to chat with it. thus making them productive in their daily activities.
We are supporting two types of data sources in this project demonstration:
Web URL-based text data
Online PDF files
These two types contain a wide range of text data and are most frequent for many use cases. See the main.py python code below to understand the app’s user interface.
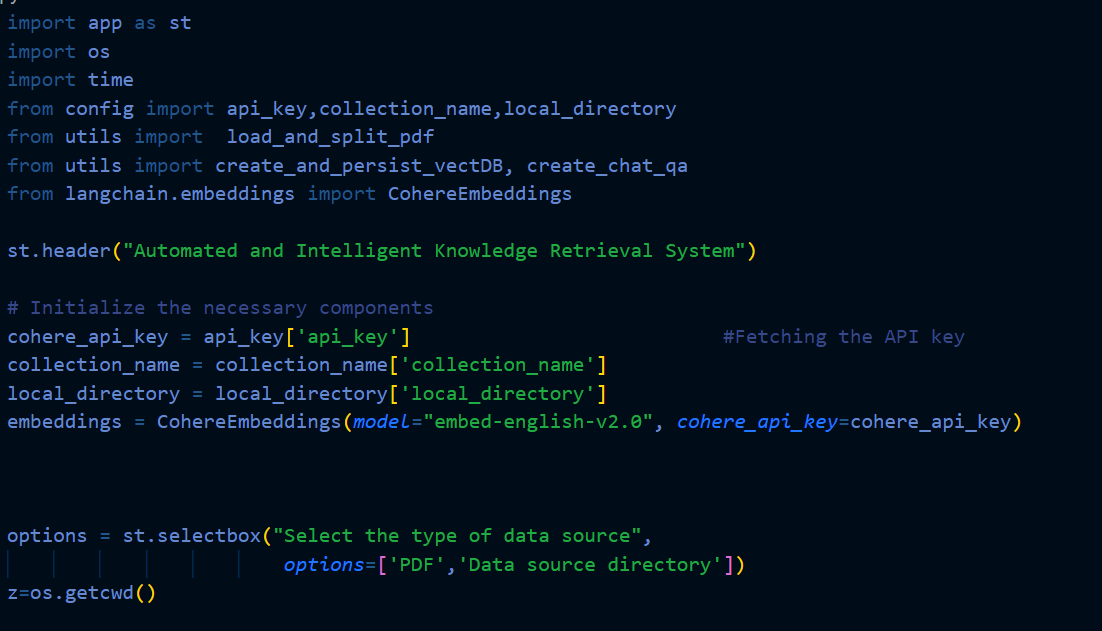
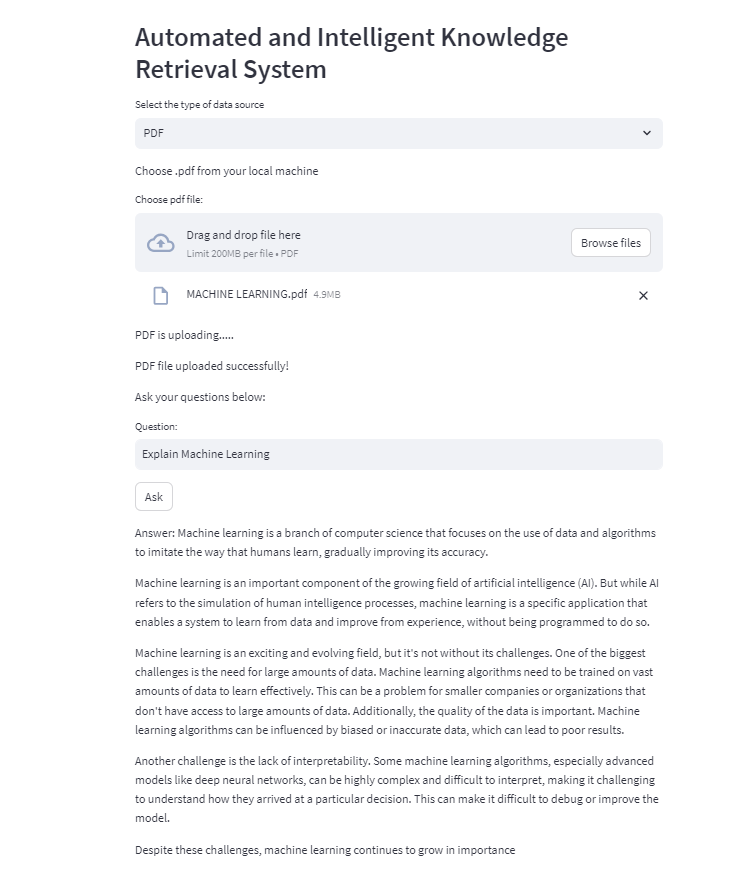
The Knowledge Retrieval System in action:
- Front-end interface built with Streamlit to provide users with an intuitive and user-friendly environment
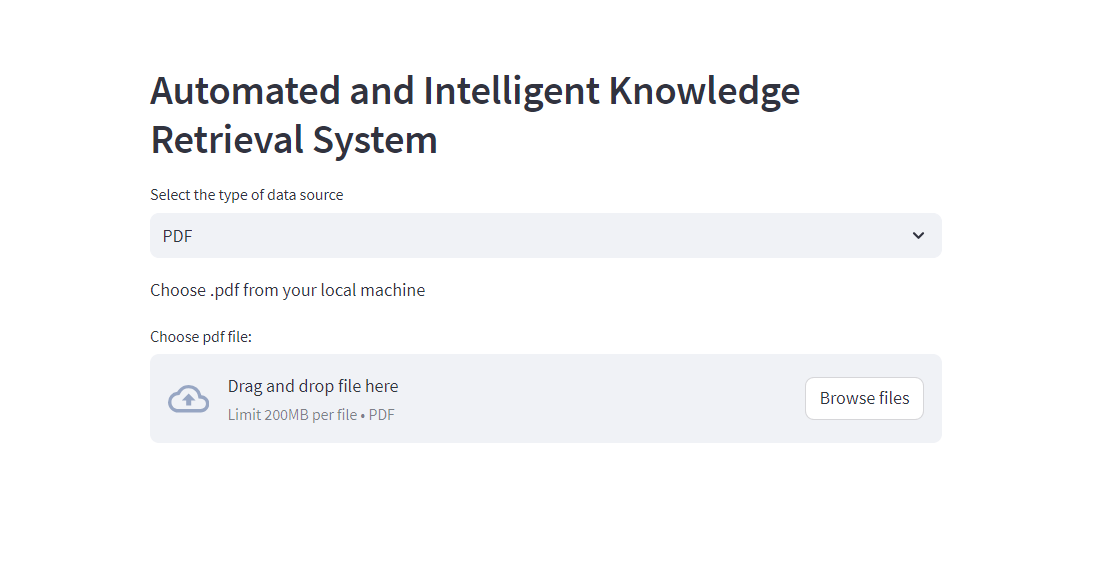
- Knowledge Retrieval System:
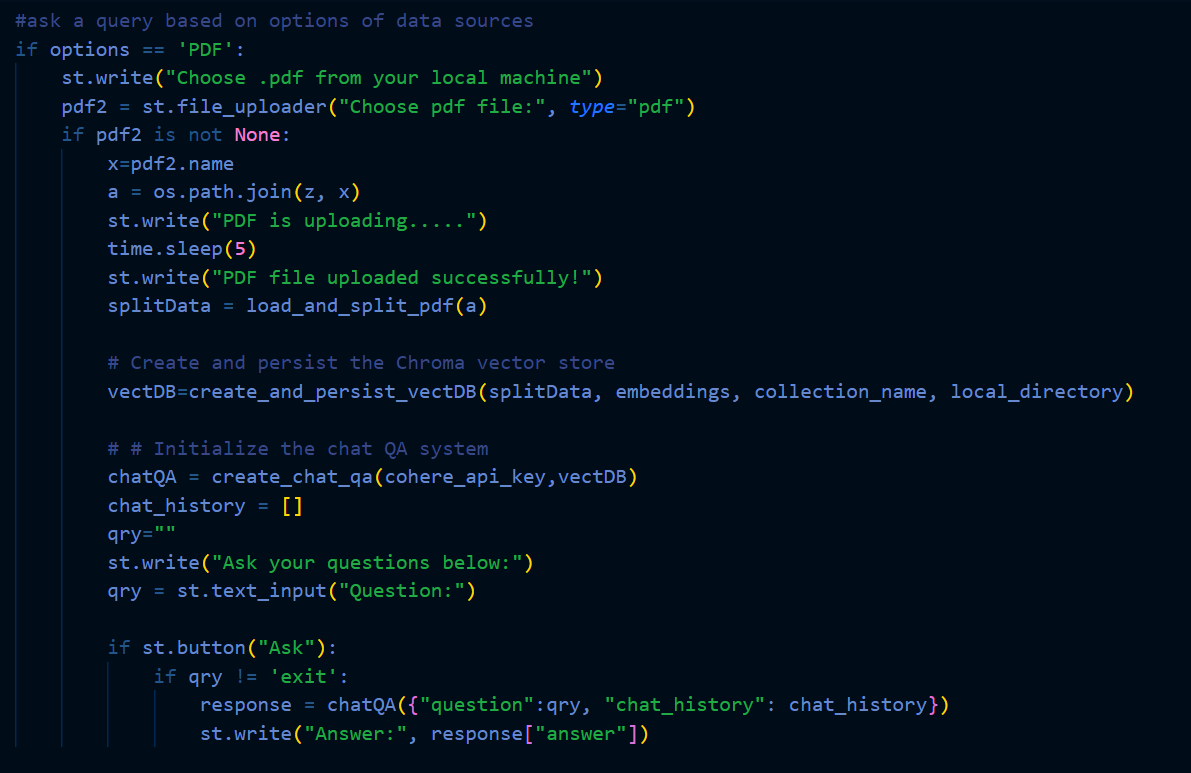
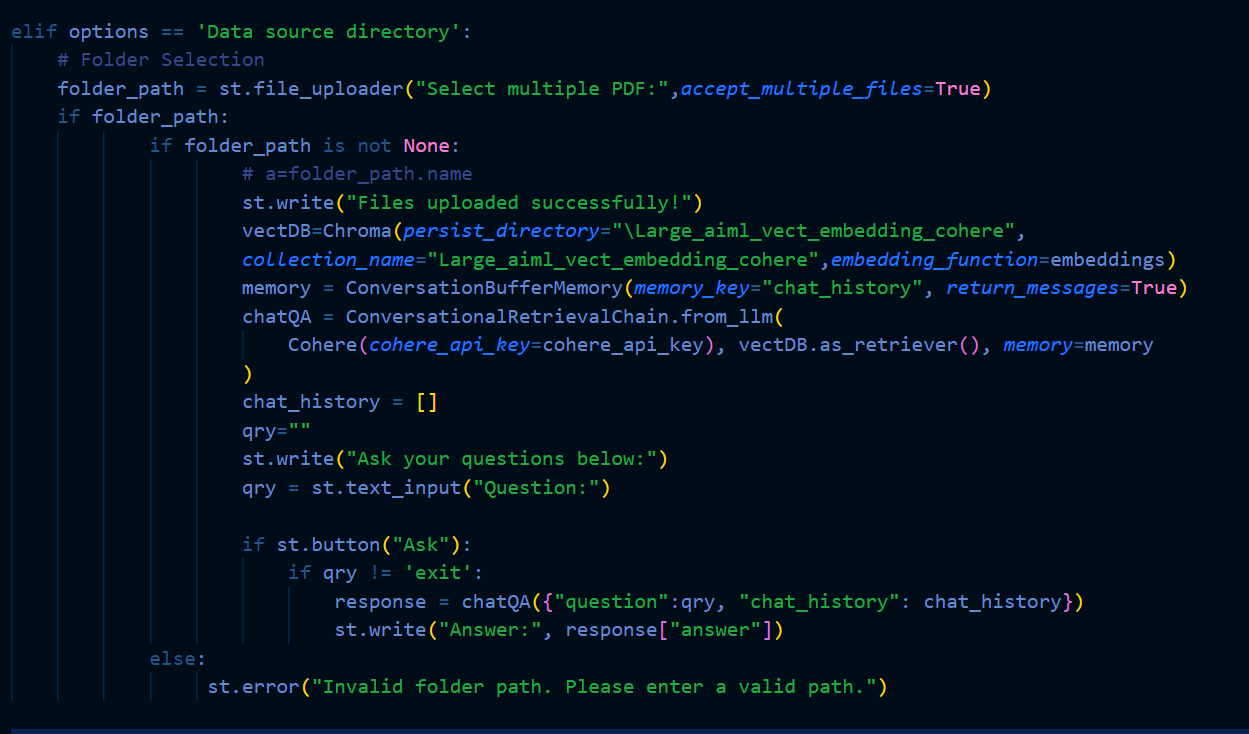
Access the Knowledge Retrieval System through the front-end, offering two distinct input options: a single PDF file or multiple PDF files for knowledge processing from the local system directly through the user interface.
- Storage in Chroma Vector Database and LLM and Langchain Processing:
Upon successful upload, store the content of the PDF file(s) in the Chroma Vector Database, representing the textual information in the form of vector embeddings. This ensures efficient storage and retrieval for subsequent tasks.
Trigger the Large Language Model (LLM) and Langchain to perform their respective tasks:
LLM retrieves similar embeddings from the Chroma Vector Database, identifying relevant information related to the uploaded PDF(s).
Langchain orchestrates the language processing tasks, enhancing the understanding and contextualization of the retrieved information.

- Answer Presentation:
Present the answers generated by LLM, incorporating the orchestrated information from Langchain. The answers are derived from the PDFs uploaded to the system, providing relevant and contextually rich responses.
References:
https://www.oracle.com/in/artificial-intelligence/generative-ai/retrieval-augmented-generation-rag/
https://www.cohesity.com/glossary/retrieval-augmented-generation-rag/
https://thenewstack.io/exploring-chroma-the-open-source-vector-database-for-llms/
https://www.techtarget.com/searchenterpriseai/definition/LangChain
Thank you for joining! Stay connected with the latest updates and insights by visiting my website www.DeepHiveMind.com. Don't forget to follow me on social media for more tech tips and discussions. Let's continue exploring the exciting world of technology together! #TechTalks #StayConnected




