

Data Science Process Frameworks

Here to share my experience in the realm of expertise:
Cloud Adoption Applied AI, ML & MLOps Microservices 2.0 Digital Portfolio & Product P&L Federated Learning (Adv. AI) IaC, X-Ops, Containers, CaaS (Container-as-a-Service| Kubernetes), CaaS Governance (HELM) Digital Product UX/UI/LCNC (PWA/Micro frontend/ Low Code No Code canvass/ Self Service Interface) Distributed Computing Cybersecurity Industry 4.0 (IIoT, Intelligent Operation Platform, OT & IT) Blockchain in Data Trust Data & Digital Transformation
A data science life cycle is a collection of specific phases executed by teams serially or parallelly in an iterative behaviour. A project can sometimes rely on the forecasting part alone or the analysis part alone, or sometimes by including both.
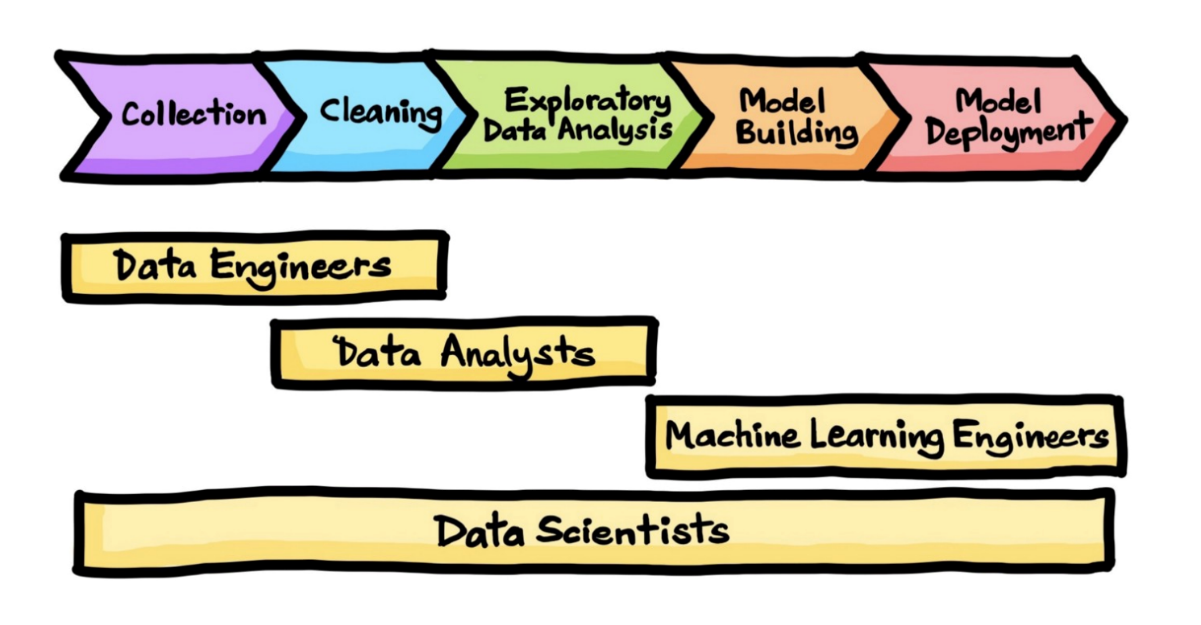
The project workflow can differ based on the selected individuals (right people) for the job. However, many data science projects go through the same general life cycle implementation steps. This article will disclose some popular data science project frameworks that can be used to determine a suitable lifecycle while starting a new project.
Traditional Data Science Life Cycles
KDD Process
SEMMA
CRISP-DM Framework
Modern Data Science Life Cycles
OSEMN
Microsoft’s TDSP
Domino’s Data Labs Life Cycle
Traditional Data Science Life Cycles
KDD Process
Data is obtained from one or more sources and rigorously improved in Knowledge Discovery in Databases (KDD), a traditional data science life cycle. It aims to remove the "noise" (useless, off-topic outliers) while laying out a step-by-step process for identifying patterns and trends that reveal crucial information.
Data Mining vs. KDD Process
In common usage, Data Mining and Knowledge Discovery in Databases (KDD) are often used interchangeably. However, a subtle distinction exists between the two. KDD encompasses the comprehensive process of deriving insights, starting from data collection and continuing through data cleaning and analysis. On the other hand, data mining is a pivotal component within the KDD process, focusing specifically on the application of algorithms to uncover patterns in data. In essence, KDD represents the entire process, with Data Mining being one of its integral steps.
The Significance of KDD
In our data-driven world, data is abundant, but its true value emerges only when it is filtered and processed for meaningful insights. Unfortunately, many overlook data filtering, impeding progress. Handling extensive datasets is challenging due to rising data capture rates and system constraints. There's a growing demand for cost-effective methods and hardware acceleration to enhance our analytical capabilities and manage large datasets effectively.
KDD Procedures
To find intriguing patterns and knowledge within data, the KDD (Knowledge Discovery in Databases) process entails a flow of discrete procedures or phases that fluidly transition from one to the next. It's vital to keep in mind that the process involves several steps, often between five and seven, depending on the viewpoint.
In this context, we shall explain and clarify the sequential order of the following seven phases:
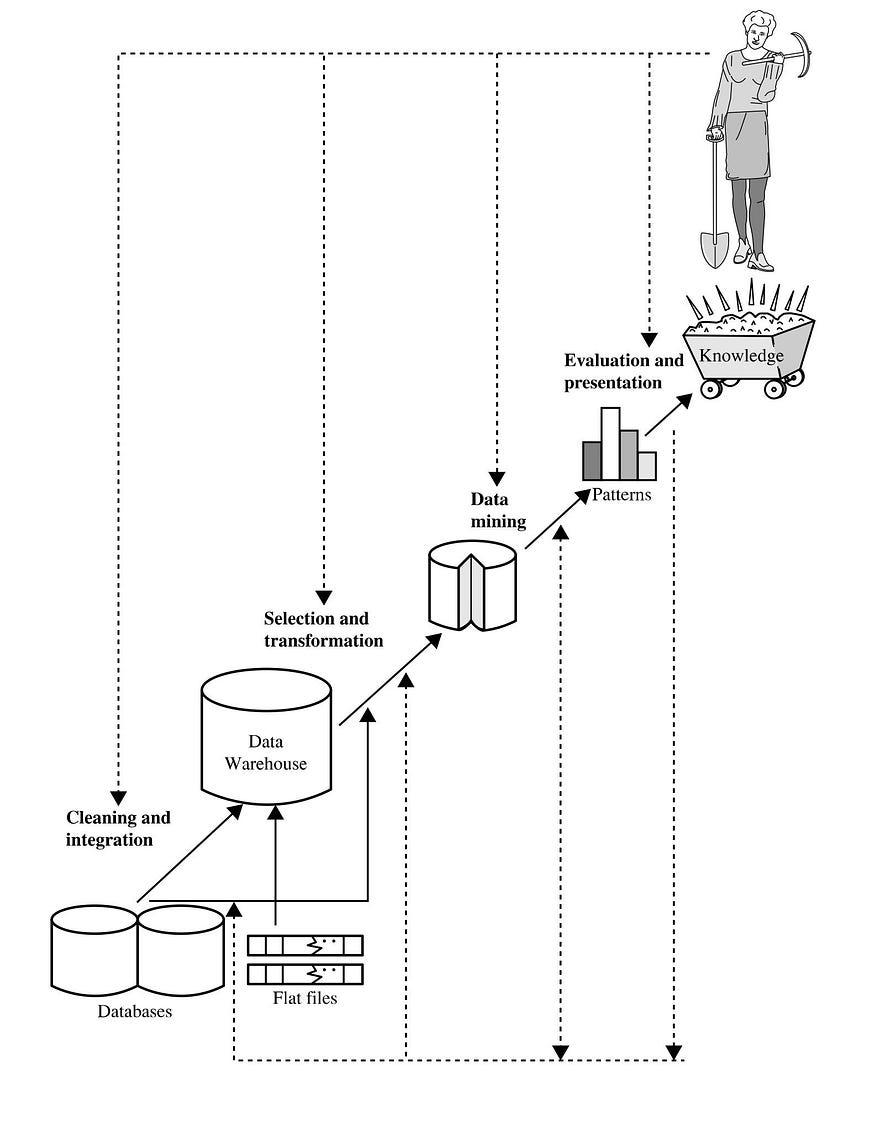
There are seven major stages in the KDD process:
Data Retrieval and Cleaning: To get started, data must be retrieved and cleaned.
Data Integration: Compiling data from many sources and making necessary adjustments.
Data Selection: Carefully selecting features of pertinent data for analysis.
Data transformation, which includes categorizing data and reshaping it into a suitable format.
Data mining: Using clever algorithms to draw forth useful patterns and insights.
Pattern Evaluation: Using pertinent metrics, determine the importance of found patterns.
Knowledge Presentation: Effectively communicating insights through data storytelling and visualization.
KDD Process: Pros and Cons
Although KDD is a great tool for organizing and carrying out data science projects, this life cycle has various benefits and drawbacks that are as follows:
Pros
• KDD aids in recognizing and forecasting consumer trends. It also emphasizes making predictions about what other items people could be likely to utilize. It aids companies in gaining a competitive edge over rivals in their industry.
• KDD is an iterative process that feeds newly gained knowledge back into the cycle (to the beginning), improving the effectiveness of predetermined goals.
• KDD facilitates effective anomaly identification by segmenting work into distinct steps throughout the entire process. We can go back and confirm the steps if we discover a problem or ambiguity at any point, and then we can go forward appropriately.
Cons
•Many concerns that contemporary data science initiatives must deal with are not addressed in this process, including data ethics, the data architecture that was selected, the roles of various teams, and the individuals who make up those teams.
•It takes time to refine the defined objectives because the process must loop back to the beginning phase. The process also includes data security. Businesses mostly seek out strategies to comprehend their clients as thoroughly as they can. It implies that they seek out more data, and protecting it is unquestionably crucial. KDD deals with data, but it doesn't guarantee its security.
• The process will utterly fail if the corporate objectives are unclear. Therefore, it is crucial to precisely describe the issue and the project's goals at the outset.
•A data science project utilizing KDD can occasionally take longer than expected because of certain chores that cannot be avoided.
SEMMA: Empowering Data Excellence
Data is the key to success in the corporate world of today, boosting competitiveness, driving expansion, and enhancing consumer experiences. It serves as the cornerstone for creating prototypes of real-time client behaviour and offers crucial information.
However, data is still ambiguous in its unprocessed state, hiding its true worth. Data needs to be cleaned up in order to facilitate analysis and in-depth investigation and to realize its full potential. Chaos could result from the current practice of accumulating data without organization. Take SEMMA, which stands for Sample, Explore, Modify, Model, and Assess. It's a tried-and-true structure that guarantees effective data use, leads businesses from unprocessed data to informed choices, and maximizes data's potential for long-term success.
SEMMA Process and Its Phases
Developed by the SAS Institute, the SEMMA process is a powerful methodology for extracting insights from raw data, comprising five essential stages: Sample, Explore, Modify, Model, and Assess. SEMMA finds applications in various domains such as Consumer Retention and procurement, Finance Factoring, and Risk Analysis, including areas like loan assessments. Let's delve into each phase:
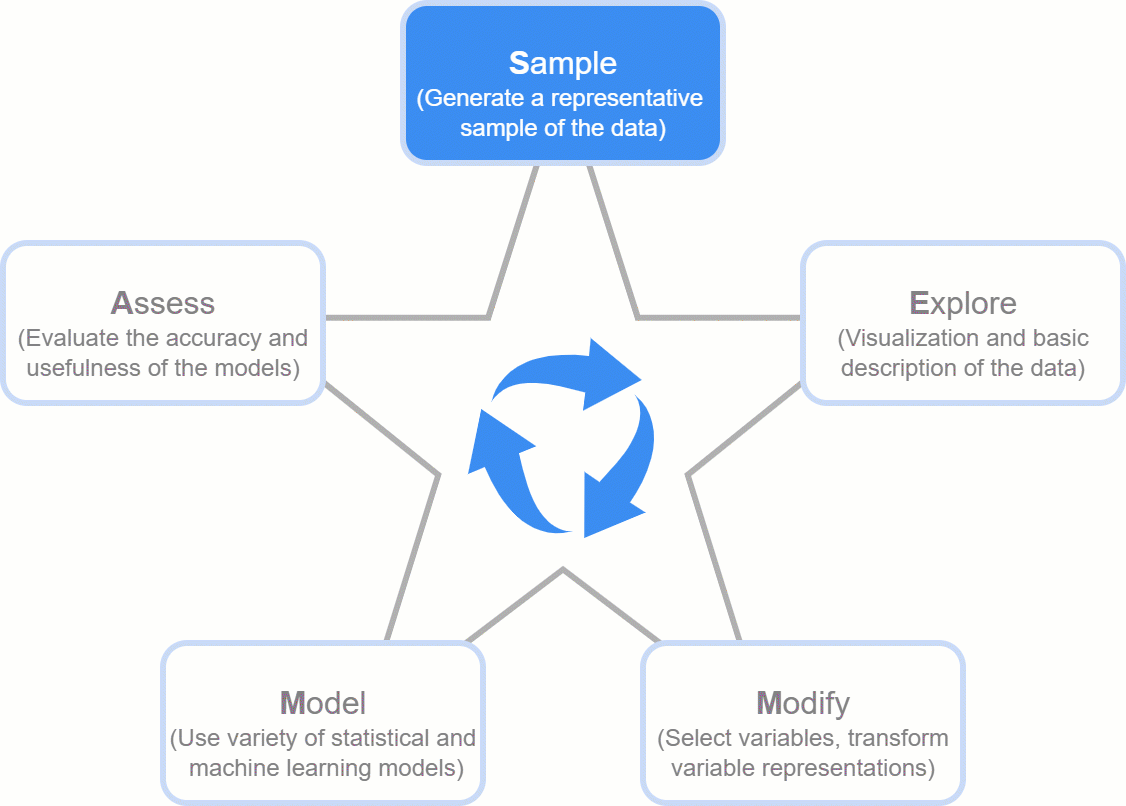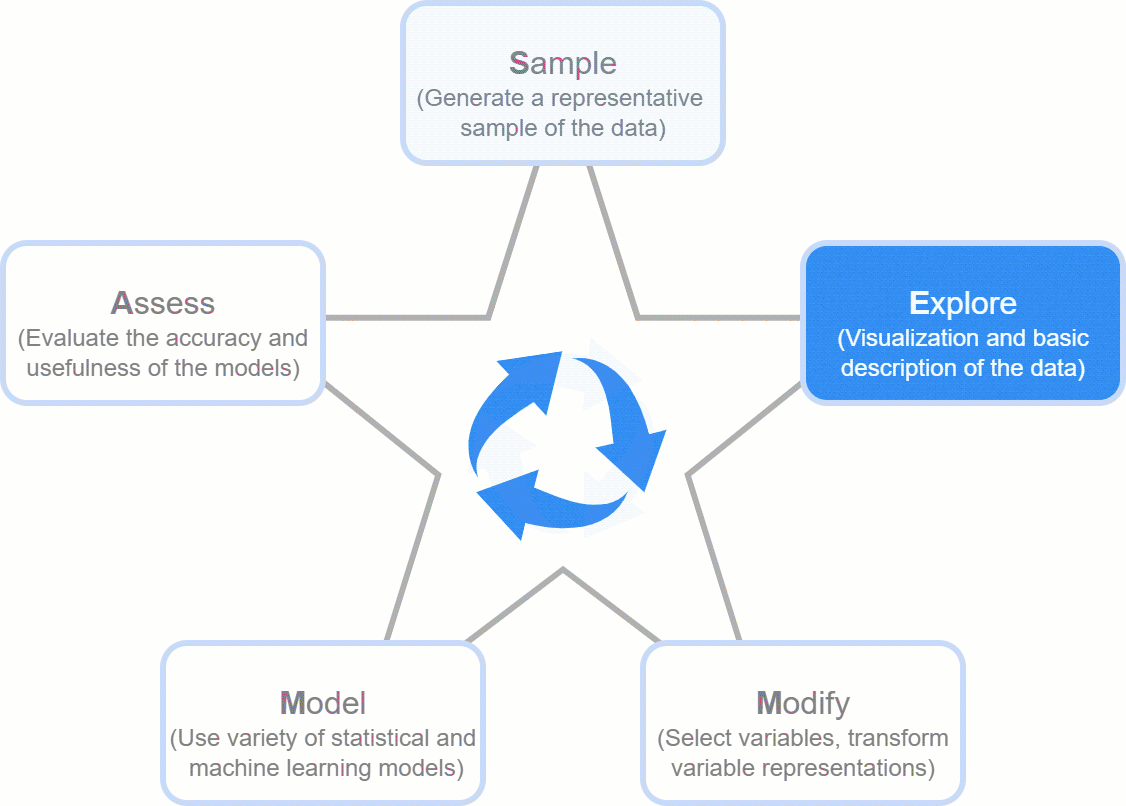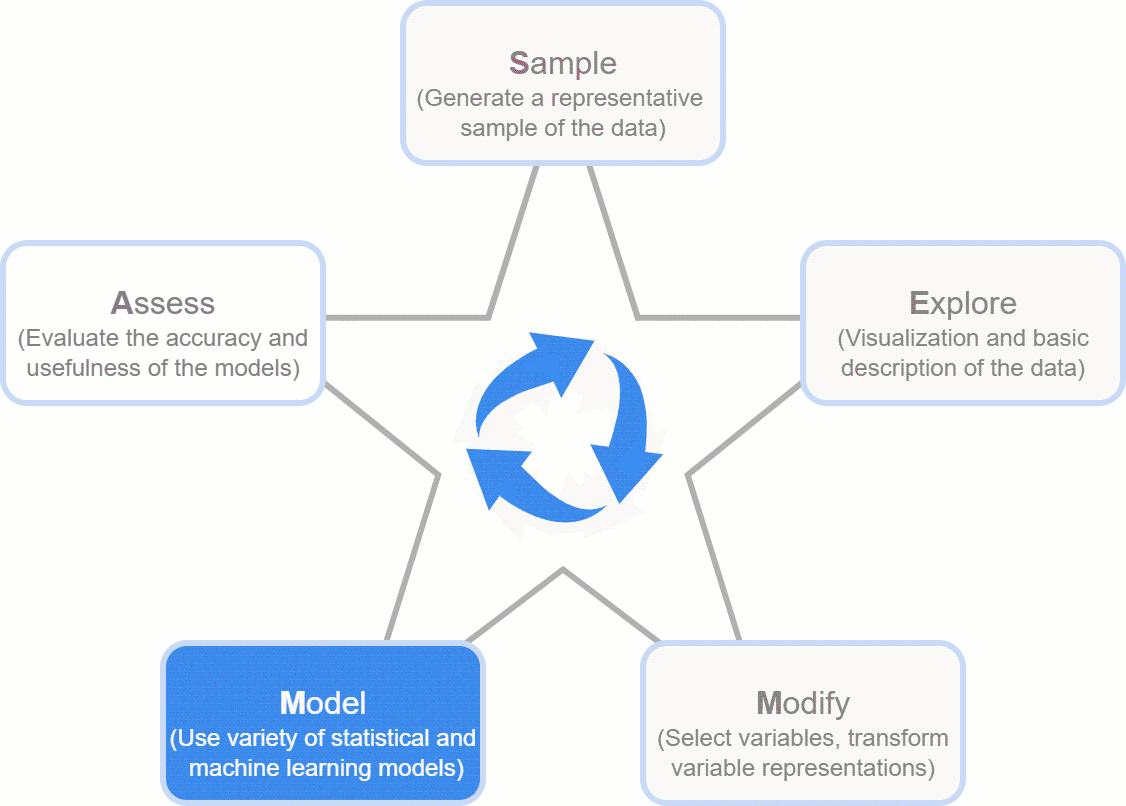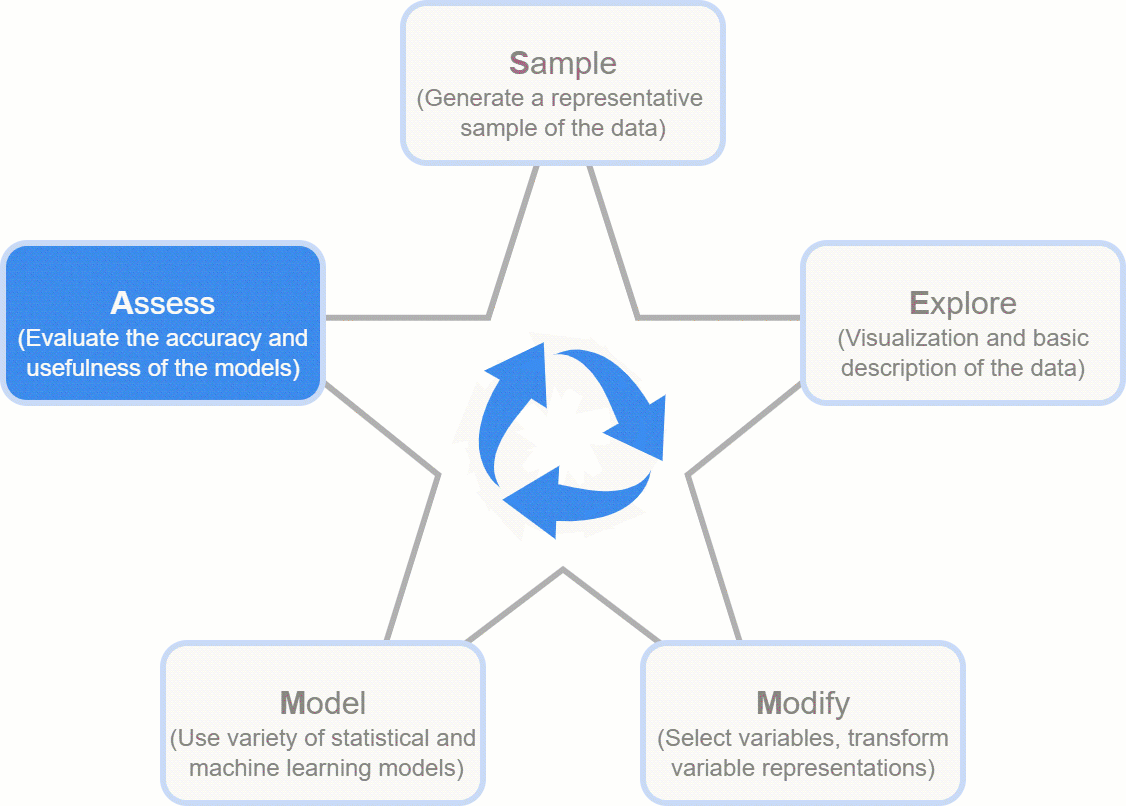
Sample: Commencing with the selection of a representative dataset from large databases, this phase identifies both dependent and independent features influencing the modelling process. After analysis, data is divided into training, testing, and validation sets.
Explore: In this stage, data exploration unfolds, encompassing single and multi-feature analysis through visual plots and statistics. It examines relationships between features, identifies data gaps, and records observations relevant to the desired outcome.
Modify: Building on insights from the previous step, data undergoes necessary transformations to prepare it for model development. If needed, the Explore phase may be revisited for further refinement.
Model: This phase focuses on employing various data mining techniques to create models that address the core business objectives.
Assess: The final step entails evaluating model effectiveness and reliability using diverse metrics applied to the initially generated testing and validation sets.
SEMMA Process vs. KDD Process
The SEMMA process closely resembles the KDD (Knowledge Discovery in Databases) process, with the distinction lying primarily in how tasks are divided across stages. The SEMMA Sample stage aligns with KDD's Data Selection. Explore parallels Data Acquisition and Cleaning, employing cleansed data for analysis. Modify corresponds to Data Transformation, while Model mirrors Data Mining. The Assess stage in SEMMA is akin to KDD's Pattern Evaluation, where pivotal decisions pave the way for subsequent actions.
CRISP-DM
In the realm of project execution, particularly within the domain of data science, the project lifecycle assumes paramount importance. Inadequate planning or ambiguity in the early stages can precipitate project failure. Consequently, organizations seek a well-defined workflow plan to ensure the efficient and effective execution of their projects. Moreover, a clear understanding of the project's overall flow is instrumental in facilitating seamless delegation of tasks among team members.
While numerous frameworks exist for executing data science-oriented projects, the CRISP-DM framework stands out as a widely embraced and popular choice within the industry.
Phases of CRISP-DM Lifecycle
CRISP-DM, which stands for CRoss Industry Standard Process in Data Mining, comprises six distinct phases that inherently delineate the execution of data science projects.
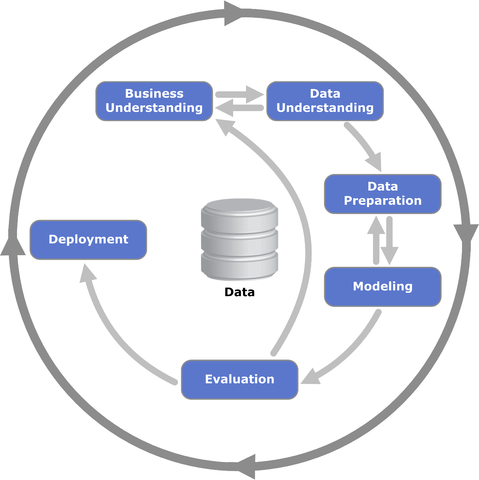
These phases are described at high-level as follows:
Business Understanding — What does the business require?
Data Understanding — What data do we have/need? Is it clean?
Data Preparation — How do we systematize the data for modeling?
Modeling —What modeling strategies should we use?
Evaluation — Which model(s) best suits the business objectives?
Deployment — How to provide results access to the stakeholders?
Phase 1: Business Understanding
The initial phase of the project lifecycle centres on comprehending the problem statement, project objectives, and requirements. Thorough documentation and the creation of flowcharts or project diagrams provide an initial project framework. This phase holds immense significance in data science projects, as a failure to grasp the objectives can have costly repercussions for investors and professionals alike.
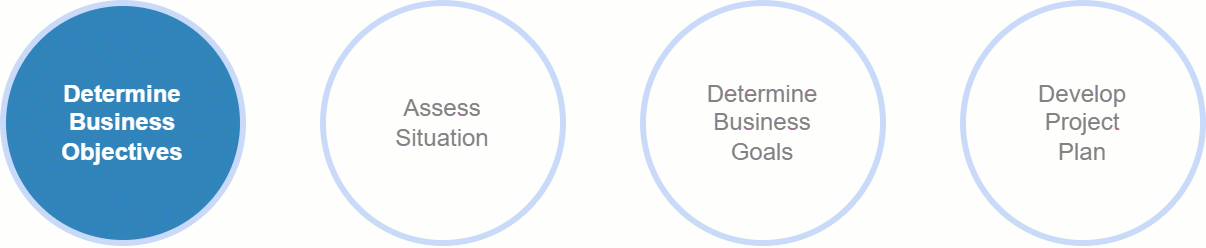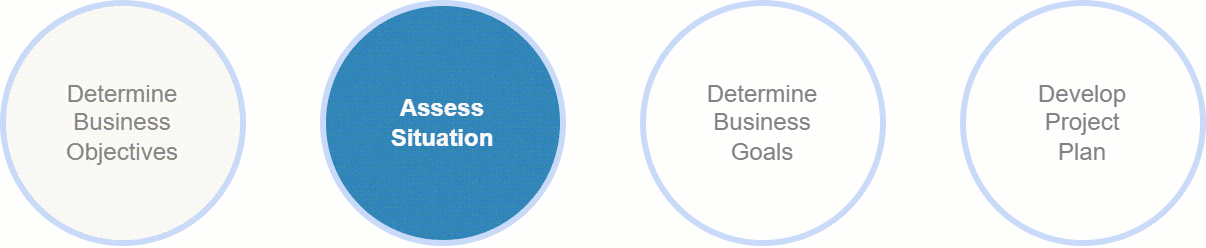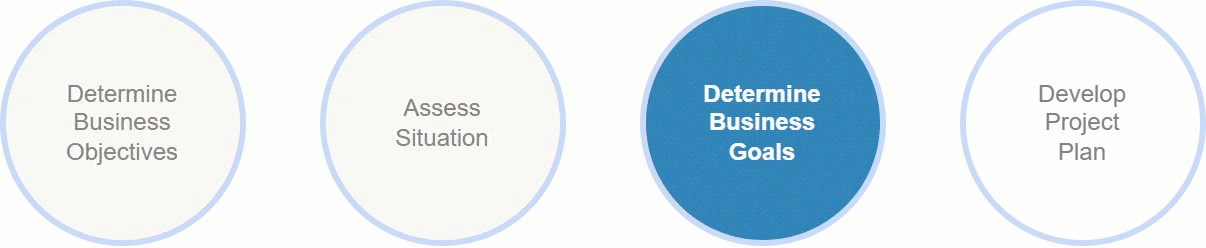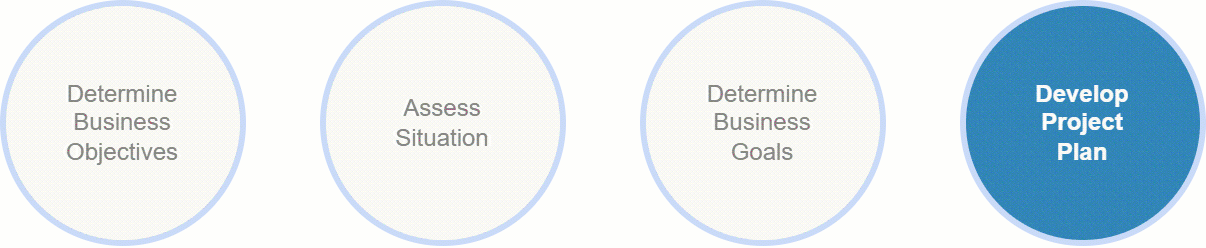
Key activities in this phase involve:
Defining Objectives: Investigating business objectives and gaining a deep understanding of customer needs.
Defining Business Success Criteria: Establishing measurable criteria for evaluating project success.
Resource Assessment: Evaluating resource availability, project requirements, associated risks, and costs.
Technical Vision: Developing a clear technical vision for seamless project execution.
Technology Selection: Identifying and selecting appropriate technologies for each project phase.
Phase 2: Data Understanding
During the second phase of the project lifecycle, the focus shifts to identifying, gathering, and scrutinizing datasets essential for achieving project objectives. Key activities in this phase include:
Data Collection: Recognizing and accumulating datasets relevant to the project's goals.
Data Loading: Importing the collected data into the chosen technology platform.
Data Examination: Scrutinizing data properties, including format, size, and reliability.
Feature Visualization: Visualizing and exploring feature characteristics within the data.
Data Integrity: Documenting any issues related to data integrity encountered during this phase.
Phase 3: Data Preparation
The third phase of the project lifecycle is dedicated to preparing the datasets for modelling, commonly referred to as data munging. This phase consumes a substantial portion of data scientists' and analysts' time, often estimated at around 80%. Key activities in this phase encompass:
Data Selection: Determining which datasets are relevant and should be included while discarding those that are not.
Data Cleaning: Addressing data quality issues, a critical step as the saying goes, "garbage in, garbage out."
Data Transformation: Analysing data behaviour and making necessary corrections and imputations where needed.
Feature Engineering: Creating new features from existing ones to enhance the modelling process.
Data Integration: If necessary, integrate data from diverse sources to enrich the dataset.
Reprocessing: Revisiting data pre-processing if it's not yet ready for the subsequent phase.

Phase 4: Modelling
In the fourth phase of the project lifecycle, the focus shifts to developing and evaluating multiple models tailored to the specific problem at hand. This phase is often considered the most exhilarating and expeditious, as modelling can often be executed with just a few lines of code. Key activities in this phase include:
Model Selection: Choosing the modelling methods that align best with the problem statement and objectives.
Data Splitting: Dividing the dataset into training, testing, and validation sets to facilitate model development and evaluation.
Model Development: Creating models, with potential hyperparameter optimizations, to address the project's objectives.
Iterative Process: Iterating through various model iterations to determine the most suitable ones based on predefined success criteria.
Evaluation: Assessing model performance against predefined success criteria and test designs.
Phase 5: Evaluation
The Evaluation phase represents a comprehensive assessment of the models developed, going beyond mere technical considerations. It involves selecting the most suitable model while aligning with both current and future business objectives. Key activities in this phase include:
Model Selection: Identifying the model that best meets the specific needs and goals of the project.
Business Success Criteria: Evaluating whether the selected model aligns with predefined business success criteria.
Model Approval: Assessing whether the developed model is suitable for business deployment.
Review and Rectification: Conducting a thorough review to identify any overlooked aspects and rectify them. Documenting findings is crucial.
Decision Points: Based on the outcomes of previous phases, determining whether to proceed with deployment, initiate a new iteration, or initiate new projects.

Phase 6: Deployment
The Deployment phase, the final step in the project lifecycle, involves putting the selected model into action to serve the business needs effectively. The objective is to ensure that the model's results are accessible to customers and stakeholders. This phase encompasses various critical activities:
Deployment Strategy: Developing a detailed strategy for deploying the model into a production environment.
Monitoring and Maintenance Plans: Establishing plans for ongoing monitoring and maintenance to prevent operational issues.
Documentation: Documenting all deployment-related processes and procedures to ensure clarity and facilitate efficient operation.
Project Summary: Preparing a comprehensive project summary that serves as a final presentation for stakeholders. This summary may also include actionable insights for future endeavours if relevant.
The Deployment phase marks the transition from development to real-world application, ensuring that the model is utilized effectively and that it continues to provide value over time.
Pros of Using CRISP-DM Lifecycle:
Generalizability: CRISP-DM offers a generalized workflow that provides clear and robust guidance for project activities, making it applicable to a wide range of data mining projects.
Iterative Improvement: The framework encourages iterative development, fostering common sense and learning as teams progress through project phases.
Ease of Enforcement: CRISP-DM can be implemented with minimal training, corporate role changes, or disputes, making it accessible to a variety of organizations.
Emphasis on Business Understanding: The initial focus on business understanding ensures a solid foundation for steering the project in the right direction.
Actionable Insights: In the final phase, stakeholders can discuss crucial issues and derive actionable insights to guide further growth and supervision.
Flexibility and Agile Principles: CRISP-DM implementation is flexible and can incorporate agile principles, allowing for adaptability and responsiveness.
Knowledge Building: The framework enables starting a project with minimal knowledge and gaining a deeper understanding through iterations, promoting empirical knowledge.
Cons of Using CRISP-DM Lifecycle:
Comparison to Waterfall: Some perceive CRISP-DM as sharing certain flaws with the Waterfall process and believe it may hinder quick iteration.
Documentation Overhead: Each phase of the project involves substantial documentation, potentially slowing down the execution of objectives and outcomes.
Not Suitable for Modern Challenges: CRISP-DM may not address the unique challenges that modern frameworks face, and it may be limited in its applicability to small teams.
Challenges with Big Data: Handling big data projects using CRISP-DM can be challenging due to the inherent characteristics of big data, often referred to as the four Vs (Volume, Variety, Velocity, and Veracity).
Modern Data Science Life Cycles
OSEMN Process Framework
In the ever-evolving landscape of AI and data science, the OSEMN framework emerges as a modern beacon for conducting data science projects seamlessly. Crafted by Hilary Mason and Chris Wiggins, OSEMN encapsulates the key phases of data science, beginning with data acquisition in "Obtain" and proceeding to data cleaning in "Scrub," data exploration in "Explore," model development in "Model," and result interpretation in "Interpret." These components align data-related tasks with machine learning endeavours while emphasizing the crucial step of interpreting results. In a collaborative context, OSEMN ensures that every team member comprehends the project framework, fostering shared understanding and streamlined project execution.
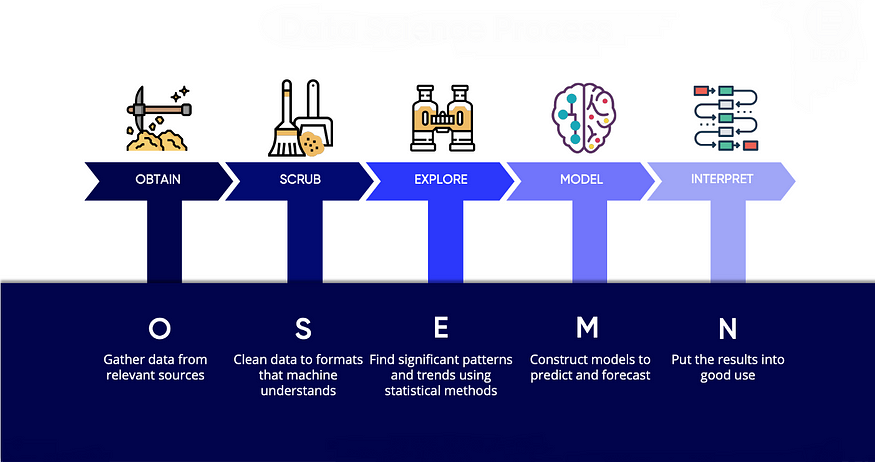
Photo by Hilary Mason and Chris Wiggins
OSEMN Process
Stage I: Obtain Data
The authors emphasize the importance of automating the data acquisition process from various sources, especially as manual processes become impractical for handling large datasets. They recommend leveraging the most suitable tools for this purpose, with Python scripts being highlighted as a versatile choice. Python scripts are lauded for their effectiveness in data science projects, enabling efficient data retrieval and manipulation. Additionally, the authors suggest the use of Application Programming Interfaces (APIs), which can be either private or public depending on the project's nature. APIs are favoured for their simplicity in facilitating data retrieval within Python, further streamlining the data procurement process.
Stage II: Scrub Data
Indeed, raw data is inherently prone to inconsistencies, often riddled with missing values, outliers, and irrelevant features. However, these issues can be effectively addressed through the application of straightforward Python scripts. The process of data cleaning demands careful consideration and significant effort, making it one of the most time-consuming steps in the data science workflow. Yet, its significance cannot be overstated, as clean and well-prepared data lay the foundation for extracting meaningful patterns and developing robust models. The authors underscore the point that conducting research using meticulously cleansed data yields more effective results compared to working with noisy and unstable data, highlighting the pivotal role of data cleaning in the data science journey.
Stage III: Explore Data
The subsequent phase involves the critical task of Exploratory Data Analysis (EDA), which holds immense significance in the data science process. EDA serves as a cornerstone in comprehending the data, offering insights that guide the transformation of data to align with specific requirements, ultimately facilitating the development of optimal models.
The authors elucidate a range of techniques instrumental in conducting EDA. These techniques encompass a spectrum of methods, including data inspection employing Command Line Interface (CLI) tools, constructing histograms to visualize data distributions, employing dimensionality reduction techniques to simplify complex datasets, leveraging clustering algorithms for pattern identification, and employing outlier detection methods to identify and address data anomalies. These techniques collectively empower data scientists to gain a comprehensive understanding of the data, laying the groundwork for informed decisions and effective model development.
Stage IV: Model Data
In the modelling phase, the primary objective is to construct multiple models, a key focal point for addressing the data problem at hand. From the array of developed models, the selection process identifies the one that exhibits superior performance.
Aligned with our ultimate goal, we deploy the chosen model to predict values using test data, interpreting the outcomes to draw actionable insights. To further enhance model performance and mitigate issues of bias and variance, we may embark on hyperparameter optimization. This step is crucial in fine-tuning the model, ultimately guarding against overfitting or underfitting, and ensuring it aligns optimally with the project's objectives.
Stage V: Interpret Results
In the concluding phase, the focus shifts to interpreting the results and deriving meaningful insights. Drawing from Richard Hamming's example of handwritten digit recognition, it's important to note that the model doesn't offer a comprehensive theory for each handwritten number but serves as a tool to differentiate between numbers effectively. This highlights a key distinction: predictive values may not always align perfectly with model interpretation. Nevertheless, the ability to interpret results opens the door to conducting intriguing experiments and further exploration.
The authors underline three crucial considerations when seeking a balance between prediction and interpretation in model selection:
Selecting Representative Data: Choose high-quality representative data that can be effectively modelled to yield meaningful insights.
Feature Selection: Opt for the most relevant and informative features from the selected representative data to enhance model performance.
Hypothesis Space and Model Constraints: Define the hypothesis space and model constraints with precision, aligning them with the transformed data to optimize the model's capabilities.
In closing, the authors leave us with valuable insights that shed light on often-overlooked aspects of the Data Science and AI journey. For those seeking to address these challenges and strengthen their skills, they recommend exploring certification programs offered by INSAID. The Global Certificate in Data Science is suggested as a comprehensive option covering foundational knowledge and machine learning algorithms, from basic to advanced levels.
Microsoft’s TDSP
With technological advancements, globalization, and some other factors, our work is expanding in our day-to-day life. Therefore, we require a system where we can execute our work in the form of projects and to direct projects in a systematic form, We need the best possible teams and a workflow plan by choosing people suitable for specific tasks.
We, people, are thriving in the project-based economy, where these project tasks are the driving force of realization, executing, completing, and yielding the outcome. The world is accepting the worth of project leadership because:
it has strategic competency and operational efficiency,
found to be teachable in education,
can be chosen as a professional path.
About Microsoft’s TDSP
The name expansion of TDSP is Team Data Science Process, and the people at Microsoft developed this framework. It is an agile based and cyclical data science-oriented procedure that can offer explanations of predictive modelling and applications which are intellectual adeptly and productive.
It aids in enhancing teamwork and knowledge by offering team positions that work most reasonably together. It incorporates the best procedures and configurations from Microsoft and other industry executives to help in the flourishing implementation of endeavours employing data science. It also permits associations to comprehend the usefulness of their analytics program.
Fundamental Segments (FS) of Microsoft’s TDSP
We can define TDSP with the help of the following segments:
FS I: Lifecycle definition of the project
FS II: Standardized structure of the project
FS III: Recommended infrastructure and resources for the project
FS IV: Recommended tools and utilities for the project implementation
FS I: Project Lifecycle Definition
We initiate by developing a high-level design for a project on data science utilizing the TDSP. We outline phases in detail that need to be concentrated on while working towards the business pursuits. The most pleasing thing is that we can still use TDSP even if already utilizing some other process like CRISP-DM or the KDD process. From the top view, all these procedures are similar in some way.
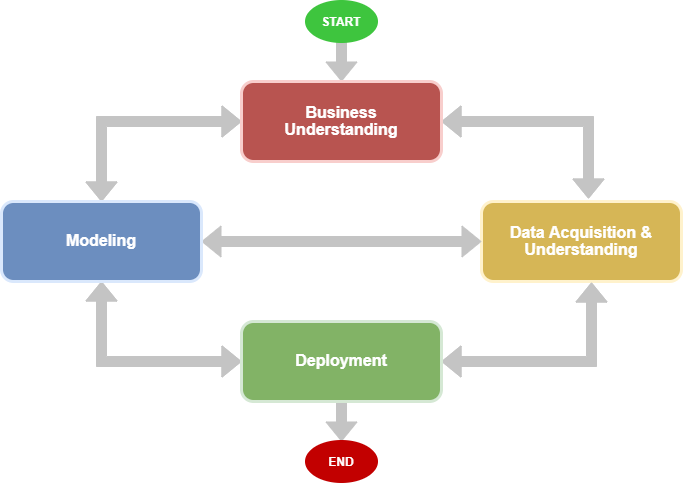
The lifecycle furnishes the evolution of savvy applications that harness the artificial power of the machine’s wisdom and intelligence to perform predictive analytics. Projects that require only exploratory data analysis can also utilize this process by removing some unnecessary parts from the lifecycle. The essential stages of the lifecycle definition, which often get executed in the iteration, are:
Business Understanding
Data Acquisition and Understanding
Modeling
Deployment
Customer Acceptance
Business Understanding
We initiate with the stakeholders to comprehend and determine the business goals and needs by formulating the questions (specific and unambiguous) that data science conventions can target. Many times, our central objective of this step is to identify critical variables that we need to forecast. We also define a high-level roadmap of people working as a team having specific roles and responsibilities. In addition, we illustrate the success criteria (metrics) of the overall project by the time it is finished. The success criteria should be SMART (Specific, Measurable, Achievable, Relevant, Time-bound). Next, we discover the relevant raw facts that help answer these questions. We are required to prepare the following deliverables in the form of documents for this stage:
A charted document that gets updated as you progress with your project, making discoveries.
The raw data sources from where their procurement transpired.
The details of schema, types, relationships, and validation rules.
Data Acquisition and Understanding
Next, we discover the relevant raw facts that help answer these questions. We may also proceed with producing high-grade data whose association with target features is comprehended. The data may reside anywhere, but we locate it and save it in our data warehouse. We may also need a strategy or a solution architecture that performs data refreshment and grade scoring if the company collects data every day. There are three tasks that we can consider while doing these operations:
Ingest the data into the environment.
Explore the data quality corresponding to the target feature.
Prepare a data pipeline that scores the refreshed data.
We are required to prepare the following deliverables in the form of documents for this stage:
Data quality, its integrity, and the relationship between features.
A solution architecture that clearly explains the data pipeline.
Verify the decisions made so far and whether to proceed further or not.
Modeling
In data modeling, we determine the best attributes and proceed with the model development concerning the target attribute utilizing several techniques. To determine the most reasonable characteristics for our model, we employ feature engineering, where we perform aggregations and modifications of data features. We generally use the associations (statistical) to understand the relationship between these features. However, domain expertise also plays an essential role in feature engineering. Once we determine the necessary attributes, we split the input data, build the models, evaluate them and determine the best solution to our questions depending upon the category of problem chosen.
Deployment
Once we finalize the models that we will utilize, we can deploy them over the production in the form of applications for our consumers. These applications may operate either in real-time or on a batch basis. It is always a great idea to develop API interfaces that can be exposed as endpoints because consumers can utilize their functionality in various applications like Online websites, spreadsheets, dashboards, and back-end applications. We should also create artifacts that explain:
The status of system health and key metrics.
A report on the modeling with the details of the deployment.
An architectural document on the final solution.
Customer Acceptance
In this part, we verify the operational efficiency of the pipeline, from gathering the data to the modeling and their deployment in the production environment that satisfies the consumer’s pursuits. We generally address two main tasks in this stage, which are:
The deployed model’s confirmation and the associated pipeline of the provided business pursuits.
Project handover to the body that will monitor the production procedure once consumers’ needs are satisfied.
As far as the artefacts are concerned in this stage, we generally create an exit report of the entire project for the consumer. It includes all the project particulars that will help in operating the system.
We can also create a summary diagram and visualize all the tasks (blued) and their associated artefacts (greened) concerning each task, and the project roles, as shown below
FS II: Standardized Project Structure
It becomes very straightforward for team fellows to access a shared folder that contains a set of reusable templates every time a new project gets initiated. Team associates can collaborate on Version Control Systems (VCS) like Git and Azure DevOps Server by storing code and associated documents. In addition, we can also use some tracking systems for projects that enable us to track jobs and attributes to acquire more reasonable cost estimates. TDSP highly recommends forming separate storage with a standardized design for each project on the VCS because it helps cultivate institutional understanding across the organization. We create a standard location where all the codes and documents will be residing and locatable. This way, different teams can understand the work completed by others and collaborate easily without conflicts. We can use a checklist concerning the questions to ensure the concerns and deliverables satisfy the quality expectations.
FS III: Requirement of Infrastructure and Resources
TDSP also recommends handling the shared allocation of resources for data science projects by incorporating them into the infrastructure. It enables teams to accomplish reproducible analysis by avoiding replication, inconsistencies, and unneeded costs. The provided tools shared with the team members allow them to share resources and track them while making a secure connection. For example, let’s say several teams are working on numerous projects and communicating utilizing various features of the infrastructure (shared).
FS IV: Requirement of Tools and Utilities
Sometimes it is grueling for the corps to introduce new strategies to the existing framework. We can utilize the functionality of tools provided by TDSP that can help reduce the obstacles and boost the consistency of the data science processes. In addition, it also facilitates in automation of some tasks like data modeling and its exploration. Individuals can also contribute to shared mechanisms and utility development if a well-defined architecture exists. Microsoft has provided tools in Azure Machine Learning with the support of both open-source and its tooling.
Pros/Cons of TDSP
Pros
It supports agile development, which underlines the necessity of delivering results in increments throughout the project.
It is familiar to people who know typical software-oriented routines like logging, bug detection, and code versioning.
The lifecycle is data science-oriented and well-understood by TDSP.
The lifecycle is very flexible with different frameworks like CRISP-DM.
The lifecycle provides detailed documentation concerning highly focused business pursuits.
Cons
It struggles with fixed-length planning, which can be formidable if we need to introduce some variation.
Some documentation delivered by Microsoft may not be proper.
This framework is great for people who desire to deliver production-level creations. It may be inappropriate for small-scale teams without any production-level outcomes.
References:
https://medium.com/international-school-of-ai-data-science/kdd-process-in-data-science-1b8716bed59f
Thank you for joining! Stay connected with the latest updates and insights by visiting my website www.DeepHiveMind.com. Don't forget to follow me on social media for more tech tips and discussions. Let's continue exploring the exciting world of technology together! #TechTalks #StayConnected




