

Cloud Data Warehouse MPP
Here to share my experience in the realm of expertise:
Cloud Adoption Applied AI, ML & MLOps Microservices 2.0 Digital Portfolio & Product P&L Federated Learning (Adv. AI) IaC, X-Ops, Containers, CaaS (Container-as-a-Service| Kubernetes), CaaS Governance (HELM) Digital Product UX/UI/LCNC (PWA/Micro frontend/ Low Code No Code canvass/ Self Service Interface) Distributed Computing Cybersecurity Industry 4.0 (IIoT, Intelligent Operation Platform, OT & IT) Blockchain in Data Trust Data & Digital Transformation
The massive growth of data and devices is having a profound impact on business. Every company in every industry around the world is being challenged to transform into a digital organization. Never have the opportunities—and the challenges—been greater. Most companies have multiple vertical silos of information. Different apps gather overlapping, sometimes conflicting, data. Unstructured data, which can include Internet of Things (IoT) data, typically is collected without a predefined data model, but needs to be connected to the rest of your data.
Databases are the bedrock for provisioning this data, and data analytics has become the tool by which this data is converted into actionable information. Trying to bring together data sets while delivering timely, accurate information can overwhelm any IT team. Data keeps accumulating, requiring more and more investment in physical infrastructure and new ways to analyze the data. Costs mount based on the need for perpetual uptime and highly trained database and system professionals.
In this blog we discuss about challenges often force organizations to only use a fraction of their data for analysis, limitation associated with Traditional Data Warehouses and how is a Modern Cloud Data Warehouse different with scale-out MPP processing.
Introduction:
Most large enterprises today use data warehouses for reporting and analytics purposes using the data from a variety of sources, including their own transaction processing systems and other databases. Data and analytics have become an indispensable part of gaining and keeping a competitive edge. But many legacy data warehouses under-serve their users, are unable to scale elastically, don’t support all data, require costly maintenance, and don’t support evolving business needs.
These challenges often force organizations to only use a fraction of their data for analysis. We call this the “dark data” problem: companies know there is value in the data they have collected, but their existing data warehouse is too complex, too slow, and just too expensive to analyze all their data.
Problem with Traditional Data Warehouses:
Expensive to set up and operate
Most data warehousing systems are complex to set up, cost millions of dollars in upfront software and hardware expenses, and can take months in planning, procurement, implementation, and deployment processes. Organizations need to make large investments to setup the data warehouse and hire a team of expensive database administrators to keep the data warehouse running queries fast and protect against data loss or system outage.
Difficult to scale
When data volumes grow or organizations need to make analytics and reports available to more users, they choose between accepting slow query performance or investing time and effort for an expensive upgrade process. In fact, some IT teams discourage augmenting data, adding users, or adding queries to protect existing service-level agreements.
Unable to handle data variety
Increasing diversity in information sources such as devices, videos, IoT sensors, and more results in increasing volume & variety of unstructured data, which creates new challenges to derive useful insights. Traditional data warehouses, implemented using relational database systems, require this data to always be cleansed before it is loaded, and to comply with pre-defined schemas. This poses a huge hurdle for analysts and data scientists, who are otherwise skilled to analyze data directly in open formats. Organizations try to handle the volume and variety of these data sources and bolt-on data lake architecture to their data warehouse to store and process all data. But, they often end up with data silos and run into error prone and slow data sync between their data warehouses and data lake.
Insufficient for modern use cases
Traditional data warehouses are designed for batch processing Extract, Transform and Load (ETL) jobs. This prevents data to be analyzed as it arrives, and in the formats (like Parquet, ORC, and JSON) in which it is stored. Traditional data warehouses also don’t support sophisticated machine learning or predictive workloads or support them in a limited fashion. Therefore, they’re unable to support modern use cases such as real-time or predictive analytics and applications that need advance machine learning and personalized experiences.
Traditional data warehouses cannot query data directly from the data lake and from open formats such as Parquet, ORC and JSON
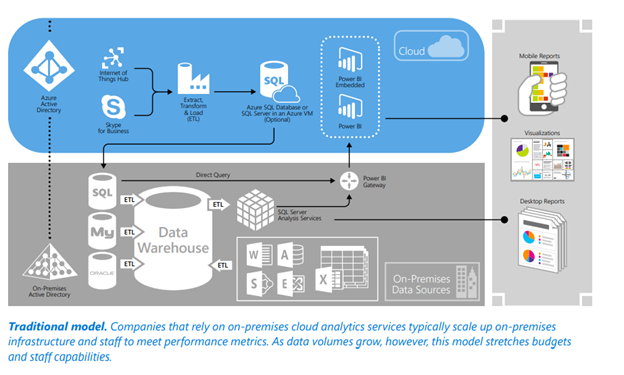
Figure 1: Traditional Database to Cloud Architecture
Modern Cloud Data Warehouse:
A modern cloud data warehouse is designed to support rapid data growth and interactive analytics over a variety of relational, non-relational, and streaming data types leveraging a single, easy-to-use interface with all the elasticity and cost efficiency cloud provides.
Modern data warehouse liberates you from the limitations of loading data into local disks before it can be analyzed. This gives you virtually unlimited flexibility to analyze the data you need, in the format you need it, and using familiar BI tools and SQL.
Power of Massively Parallel Processing:
Massively parallel processing (MPP) is a storage structure designed to handle the coordinated processing of program operations by multiple processors. This coordinated processing can work on different parts of a program, with each processor using its own operating system and memory. MPP processors can have up to 200 or more processors working on application and most commonly communicate using a messaging interface. MPP works by allowing messages to be sent between processes through an “interconnect” arrangement of data paths. This allows MPP databases to handle massive amounts of data and provide much faster analytics based on large datasets.
What is an MPP Database?
An MPP Database (short for massively parallel processing) is a storage structure designed to handle multiple operations simultaneously by several processing units.
A leader node handles communication with each of the individual nodes. The computer nodes carry out the process requested by dividing up the work into units and more manageable tasks. An MPP process can scale horizontally by adding additional computing nodes rather than having to scale vertically by adding more servers.
The more processors attached to the data warehouse and MPP databases, the faster the data can be sifted and sorted to respond to queries. This eliminates the long time required for complex searches on large datasets.
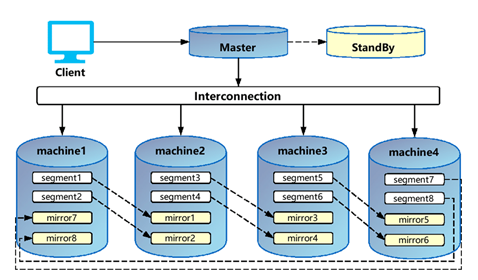
Figure 2: MPP Database Architecture
Types of MPP Database Architecture:
There are two common ways IT teams set up database architecture.
Grid computing
Computer clustering
1. Grid Computing
With grid computing, multiple computers are used across a distributed network. Resources are used as they are available. While this reduces hardware costs, such as server space, it can also limit capacity when bandwidth is consumed for other tasks or too many simultaneous requests are being processed.
2. Computer Clustering
Computer clustering links the nodes, which can communicate with each other to handle multiple tasks simultaneously. The more nodes that are attached to the MPP database, the faster queries will be handled.
Within the MPP architecture, there are several hardware components.
Processing Nodes
Processing nodes can be considered the building blocks for MPP. Nodes are simple homogenous processing cores with one or more processing units. A node might be a server, a desktop PC, or a virtual server.
High-Speed Interconnect MPP breaks down queries into chunks, which are distributed to nodes. Each node works independently on its part of the parallel processing system tasks. It takes centralized communication and a high bandwidth connection between nodes. This high-speed interconnect is typically handled by ethernet or a distributed fiber data interface.
Distributed Lock Manager
A distributed lock manager (DLM) coordinates resource sharing when external memory or disk space is shared among nodes. The DLM handles resource requests from nodes and connects them when resources are available. DLM also helps with data consistency and recovery of node failures.
MPP Database vs. SMP Database:
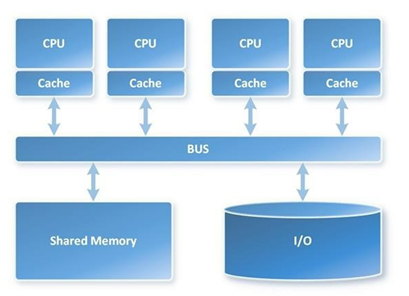
Figure 3: Symmetric Multiprocessor (SMP)
SMP databases can run on more than one server, but they will share resources in a cluster configuration. The database assigns a task to an individual CPU, no matter how many CPUs are connected to the system
In comparison to MPP databases, SMP databases usually have lower administrative costs. The tradeoff is often speed
An MPP database sends the search request to each of the individual processors in the MPP. When two MPP databases use an interconnect, search times can be nearly half the time of an SMP database search. It is the most efficient way to handle large amounts of data
A typically SMP database used for email servers, small websites, or applications that don’t require significant computing power, such as recording timecards or running payroll. MPP databases are most commonly used for data warehousing of large datasets, big data processing, and data mining applications.
MPP Data Warehouse vs Traditional Data Warehouse:
| Capability | MPP Data Warehouse | Traditional Data Warehouse |
| Elasticity | Scale up for increasing analytical demand and scale down to save cost during lean periods – on-demand and automatically. | Hard limitations on growing or shrinking the storage and compute, slow to adopt, over provisioning for future demands, low capacity utilization |
| Performance | Leverage easily scalable cloud resources for compute and storage, caching, columnar storage, scale-out MPP processing, and other techniques to reduce CPU, disk IOs, and network traffic | Depend on fixed compute and storage resources, leading to performance ceiling and contention during data integration and loading activities. |
| Cost | Eliminate fixed costs of infrastructure and allow organizations to grow their data warehouse and evaluate new data sources with minimal impact on cost. High availability and built-in security eliminates cost of failure. | Need millions of dollars of up-front investment in hardware, software, and other infrastructure, and significant cost of maintaining, updating, and securing the data warehouse. caling may not result in economies of scale, as more fixed investment is required every time capacity maxes out. |
| Use cases | Work across a variety of modern analytical use cases because of versatility and seamless integration with other purpose built engines | Insufficient for predictive analytics, real-time streaming analytics and machine learning use cases. |
| Simplicity | Easy to deploy and easy to administer; avoid knobs and use smart defaults to offer better out-of-the-box performance than traditional data warehouses. Hardware upgrades happen seamlessly | Rolling out a data warehouse is often slow and painful. On an ongoing basis, a lot of undifferentiated heavy lifting is involved in database administration, including in |
provisioning, patching, monitoring, repair, backup and restore. |
| Scale | Scale in and out automatically to absorb variability in analytical workloads and support thousands of concurrent users. Quickly scale up to accommodate high analytical demand and data volume and scale down when demand subsides to save cost. Scale out to exabytes of data without needing to load it into local disks. | Scale in and out automatically to absorb variability in analytical workloads and support thousands of concurrent users. Quickly scale up to accommodate high analytical demand and data volume and scale down when demand subsides to save cost. Scale out to exabytes of data without needing to load it into local disks. |
| Rich ecosystem | Work with a wide variety of ETL, querying, reporting and BI, and advanced analytics tools. | May only work with proprietary tools or specific third-party vendors. Integrations may be difficult to implement. |
| Data ingestion | Take advantage of relational, non-relational, and streaming data sources. | Optimized for relational data sources |
| Open data
formats | Load and query data from, and unload data to, open formats,
such as Parquet, ORC, JSON, and Avro. Run a query across
heterogeneous sources of data. | May not support open data formats |
MPP Databases Used For?
MPP databases are best suited for an organization that can run queries in a data warehouse at the same time without lengthy response times.
MMP databases are also especially helpful for centralizing massive amounts of data in a single location, such as a data warehouse. Central storage allows users at different locations to access the same set of data. Everybody works off a single source of truth rather than data silos, ensuring everyone has the most recent data available. There is no worry about whether you have the updated version or access to different data than others.
For larger organizations,** this centralized resource makes it easier to uncover insights**, connect data dots that may not be apparent at first, and even build dashboards that contain more relevant information than those built from data that is fragmented. Finally, MPP is usually best suited to handle structured data sets as opposed to models such as data lakes
Advantages of MPP Architecture:
Besides the speed of processing queries, there are other advantages of deploying an MPP architecture.
Scalability: You can scale out in a nearly unlimited way. MPP databases can add additional nodes to the architecture to store and process larger data volumes.
Cost-efficiency: You don’t necessarily have to buy the fastest or most expensive hardware to accommodate tasks. When you add more nodes, you distribute the workload, which can then be handled with less expensive hardware.
Eliminating the single point of failure: If a node fails for some reason, other nodes are still active and can pick up the slack until the failed node can be returned to the mix.
Elasticity: Nodes can be added without having to render the entire cluster unavailable.
Benefits of Data Warehousing over Traditional Data Warehouses:
The perfect foundation for a modern analytics pipeline
Flexibility to query seamlessly across the data warehouse and data lakes
A rich ecosystem for big data
Easy, fast, and flexible loading
Security and compliance
Increased agility and reduced cost
Few MPP Databases:
AWS Redshift is 10 times faster than other data warehouses. You can setup and deploy a new data warehouse in minutes
Azure SQL Data Warehouse is a massively parallel processing (MPP) relational database management system (RDBMS) data warehouse based on Microsoft SQL Server.
References :
[PowerPoint Presentation (awsstatic.com)](https://d1.awsstatic.com/products/Redshift/Amazon Data Warehouse EBook_111518.pdf)
[Microsoft Data Warehouses and BI White Paper.pdf (marquam.com)](https://www.marquam.com/Documents/Microsoft Data Warehouses and BI White Paper.pdf)
[https://www.marquam.com/Documents/Microsoft%20Data%20Warehouses%20and%20BI%20White%20Paper.pdf](https://www.marquam.com/Documents/Microsoft Data Warehouses and BI White Paper.pdf)
Thank you for joining! Stay connected with the latest updates and insights by visiting my website www.DeepHiveMind.com. Don't forget to follow me on social media for more tech tips and discussions. Let's continue exploring the exciting world of technology together! #TechTalks #StayConnected




